Ở bài viết Quy luật Empirical và điểm dị biệt outliers trong thống kê, chúng ta đã tìm hiểu về khái niệm cũng như bản chất của điểm dị biệt. Phần nội dung tiếp sau đây, chúng ta sẽ thực hành các phương pháp phát hiện điểm dị biệt trên tập dữ liệu có tên 350 – DLTH 4 – OUTLIER.sav của ebook SPSS 26 Phạm Lộc Blog. Lưu ý, để thực hiện các phương pháp nhận diện và xử lý điểm dị biệt, trong dữ liệu luôn phải có cột biến số thứ tự của quan sát trong mẫu. Cụ thể trong dữ liệu này, biến số thứ tự trùng với ID phiếu khảo sát.
1. Phát hiện điểm dị biệt bằng bảng tần số SPSS
Thực hiện thống kê tần số Frequency cho tất cả các biến có giới hạn giá trị, điểm dị biệt là các điểm nằm ngoài vùng giới hạn giá trị của biến. Cụ thể trong ví dụ này, chúng ta thống kê tần số cho biến GioiTinh (Giới tính). Kết quả cho thấy có ba giá trị dị biệt là 3, 11, 22 với tần số xuất hiện lần lượt là 4, 1, 1.
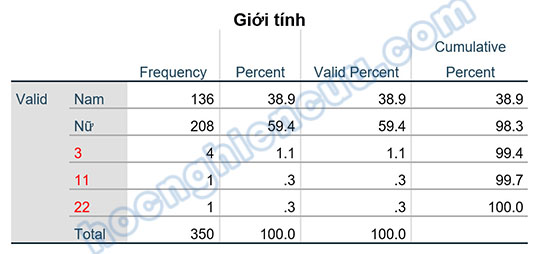
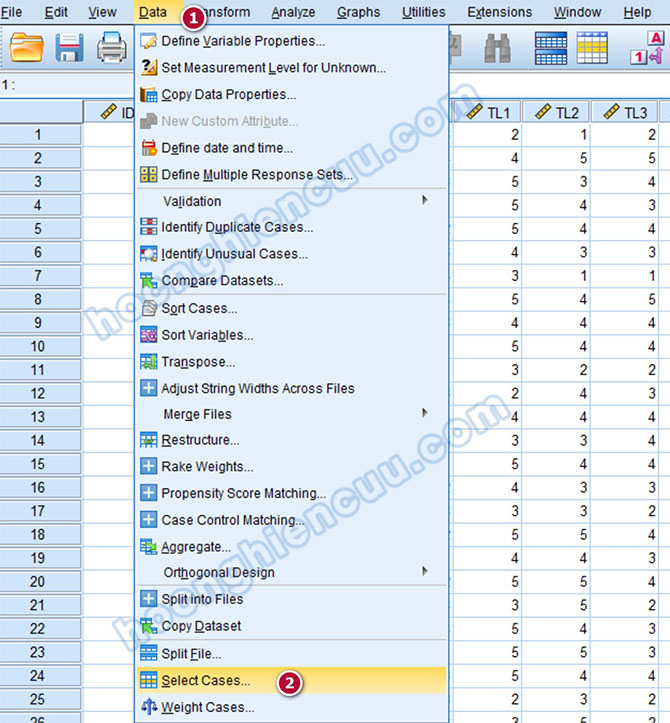
Với giá trị dị biệt 3, chúng ta sẽ rà soát lại bốn phiếu khảo sát tương ứng để điều chỉnh về 1 hoặc 2. Trong giao diện SPSS, vào Data > Select Cases…
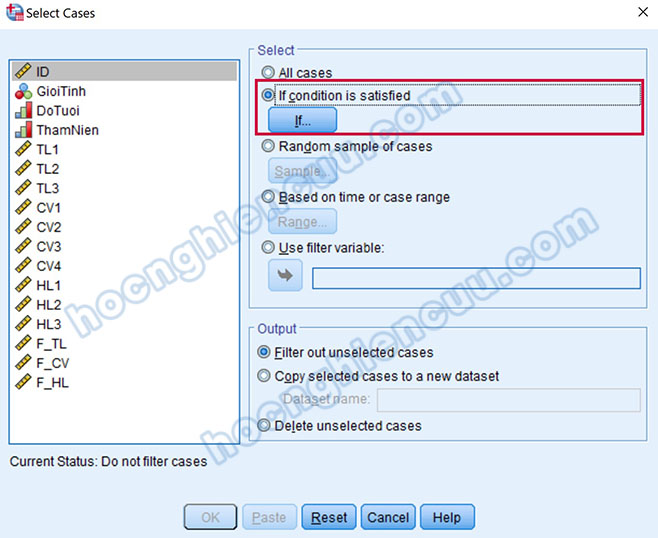
Hộp thoại Select Cases xuất hiện, chúng ta tích chọn vào If condition is satisfied và nhấp vào nút If… ngay bên dưới.
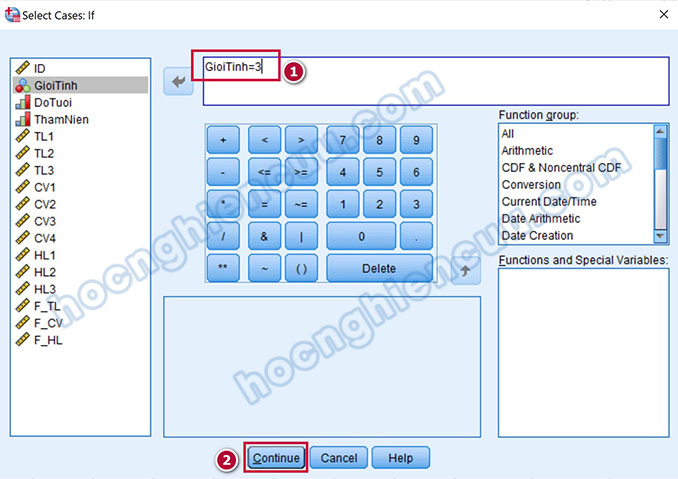
Hộp thoại Select Cases: If xuất hiện, chúng ta gõ hàm GioiTinh=3 (GioiTinh là tên biến) để yêu cầu phần mềm lọc ra các quan sát mà biến GioiTinh có giá trị 3. Nhấp vào Continue để quay về cửa sổ Select Cases, tiếp tục chọn OK để kết thúc lệnh.
Quay lại giao diện Data View, chúng ta sẽ thấy sự xuất hiện của một biến mới có tên filter_$, nhấn phải chuột vào tên biến filter_$, chọn Sort Descending.
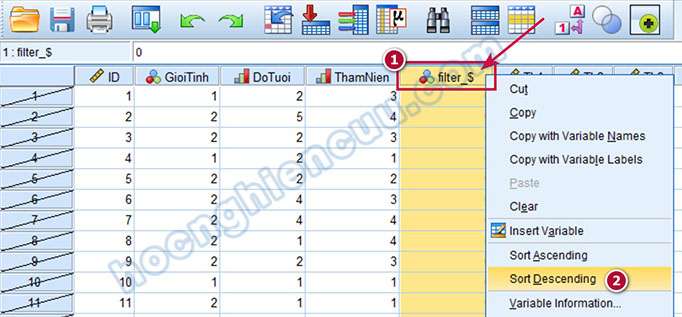
Chúng ta sẽ thấy bốn quan sát có GioiTinh bằng 3 sẽ được đưa lên trên cùng. Rà soát ID của bốn quan sát này với phiếu khảo sát thu về để điều chỉnh giá trị biến GioiTinh cho phù hợp.
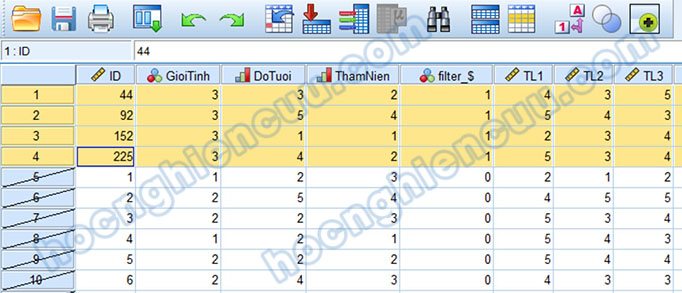
Khi chỉnh sửa xong, chúng ta cần trả dữ liệu về trạng thái chưa lọc để có thể thực hiện các phân tích, kiểm định khác. Vào lại Data > Select Cases… Lúc này tại hộp thoại Select Cases chúng ta sẽ tích vào All cases, sau đó nhấp OK để bỏ chế độ lọc.
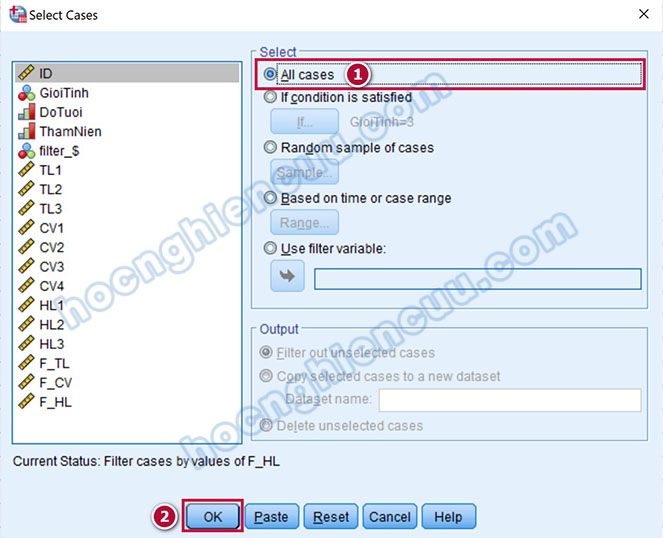
Ở giao diện Data View, nhấn phải chuột vào tên biến ID, chọn Sort Ascending để trả dữ liệu về trạng thái ban đầu. Chúng ta cần làm bước này để tránh ảnh hưởng đến giá trị Durbin-Watson dùng cho việc kiểm tra giả định tự tương quan chuỗi bậc nhất nếu về sau chúng ta thực hiện hồi quy tuyến tính trên tập dữ liệu này.
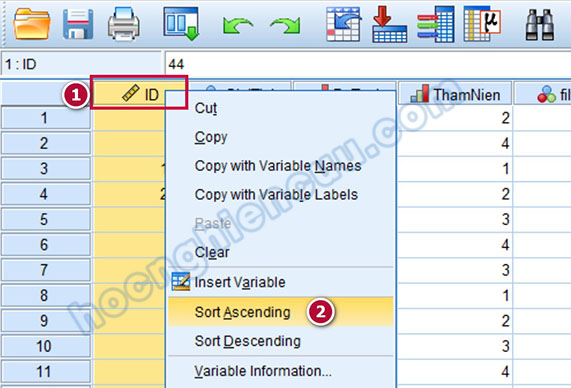
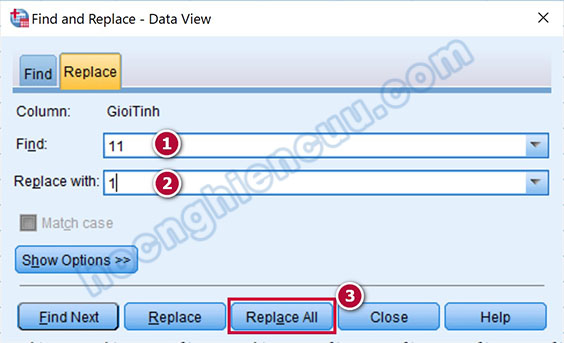
Đối với hai giá trị dị biệt 11, 22, lý do xuất hiện thường là do lỗi nhập liệu, chúng ta sửa 11 thành 1 (Nam) và 22 thành 2 (Nữ). Trong giao diện Data View, nhấp chuột vào tên biến GioiTinh để chọn toàn bộ cột. Nhấn tổ hợp phím Ctrl + H hoặc vào Edit > Replace để mở hộp thoại Find and Replace. Tại đây, nhập giá trị 11 vào mục Find, nhập giá trị 1 vào mục Replace with và nhấp vào Replace All, thực hiện tương tự với giá trị 22.
2. Phát hiện điểm dị biệt bằng bảng kết hợp SPSS
Thực hiện thống kê bảng kết hợp Custom Tables để đánh giá sơ bộ mối quan hệ các biến, điểm dị biệt là các điểm vi phạm tính logic thông tin. Cụ thể trong ví dụ này, chúng ta thống kê bảng kết hợp cho hai biến DoTuoi (Độ tuổi) và ThamNien (Thâm niên).
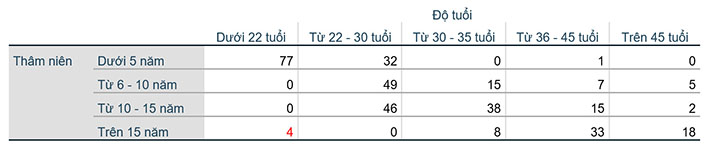
Nhận thấy sự bất thường ở đây khi có bốn quan sát ở độ tuổi dưới 22 nhưng có thâm niên làm việc trên 15 năm (vì độ tuổi lao động theo quy định phải từ 18 tuổi trở lên). Chúng ta sẽ rà soát lại bốn phiếu khảo sát này để kiểm tra nguyên nhân xuất hiện giá trị dị biệt. Thực hiện lọc giá trị Select Cases như trường hợp thống kê tần số. Trong hộp thoại Select Cases: If, chúng ta gõ hàm DoTuoi=1 & ThamNien=4 (DoTuoi, ThamNien là tên biến) để yêu cầu phần mềm lọc ra các quan sát thỏa hai điều kiện cùng lúc: biến DoTuoi có giá trị 1 và biến ThamNien có giá trị 4.
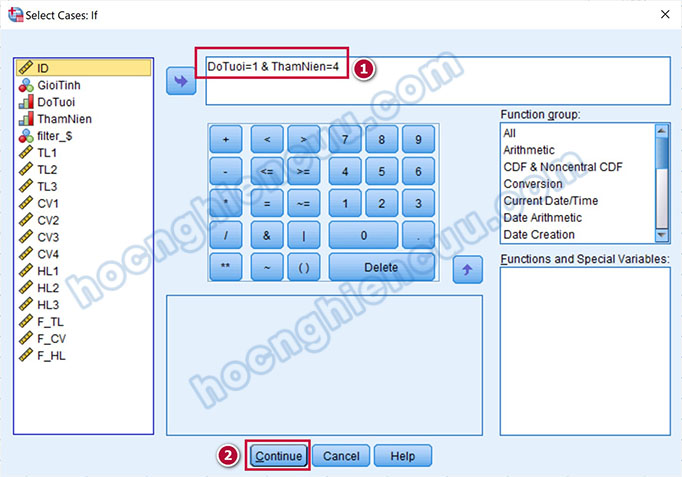
Quay lại giao diện Data View, nhấn phải chuột vào tên biến filter_$, chọn Sort Descending. Rà soát ID của bốn quan sát dị biệt với phiếu khảo sát thu về để điều chỉnh dữ liệu biến cho phù hợp. Sau đó, cũng thực hiện trả dữ liệu về trạng thái ban đầu.