Phân tích nhân tố (Factor Analysis) hay phân tích nhân tố khám phá (Exploratory Factor Analysis) là một kỹ thuật xử lý định lượng với mục đích rút gọn một tập hợp k biến quan sát thành một tập F (với F < k) các nhân tố có ý nghĩa hơn.
1. Giới thiệu về phân tích nhân tố
Trong nghiên cứu, chúng ta xây dựng nhiều câu hỏi đo lường, mỗi câu hỏi đại diện cho một biến quan sát. Khi vấn đề nghiên cứu càng đi sâu, lượng câu hỏi và các biến quan sát sẽ tăng lên, dẫn đến việc phân tích vấn đề nghiên cứu qua từng biến quan sát như vậy trở nên vô cùng phức tạp và gặp nhiều khó khăn. Các nhà nghiên cứu nhận ra rằng, không phải toàn bộ các biến quan sát đều mang một ý nghĩa tách biệt hoàn toàn, mà một số biến có cùng tính chất với nhau, tương quan chặt chẽ nhau. Những biến quan sát cùng tính chất như vậy có thể được xếp chung với nhau thành một nhân tố, và thay vì đi đo lường một số lượng lớn biến quan sát ban đầu, các nhà nghiên cứu chỉ cần đo lường một số lượng ít hơn các nhân tố mới được hình thành, điều này giúp tiết kiệm thời gian, công sức và kinh phí cho người nghiên cứu.
2. Tiêu chuẩn phân tích nhân tố EFA
2.1 Hệ số KMO (Kaiser-Meyer-Olkin)
Hệ số KMO là chỉ số dùng để đánh giá độ lớn của hệ số tương quan giữa hai biến với độ lớn của hệ số tương quan từng phần của chúng. Khái niệm này tương đối phức tạp để giải thích, phạm vi tài liệu này sẽ không đi sâu vào định nghĩa chỉ số này cũng như công thức tính. Kaiser (1974)[1] cho rằng, trị số của KMO phải đạt giá trị 0.5 trở lên (0.5 ≤ KMO ≤ 1) thì phân tích nhân tố mới thích hợp, nếu KMO dưới 0.5 nhà nghiên cứu cần cân nhắc thu thập thêm dữ liệu hoặc xem xét loại đi các biến quan sát ít ý nghĩa. Hutcheson & Sofroniou (1999)[2] đề xuất một số ngưỡng giá trị KMO như sau:
- KMO ≥ 5: mức chấp nhận tối thiểu
- 5 < KMO ≤ 0.7: bình thường
- 7 < KMO ≤ 0.8: tốt
- 8 < KMO ≤ 0.9: rất tốt
- KMO > 9: xuất sắc
[1] Kaiser, An index of factorial simplicity, Psychometrika, 1974.
[2] Hutcheson & Sofroniou, The Multivariate Social Scientist, Sage, London, 1999.
2.2 Kiểm định Bartlett (Bartlett’s test of sphericity)
Giả định rất quan trọng trong EFA là các biến quan sát đưa vào phân tích cần có sự tương quan với nhau. Thay vì đánh giá dựa vào ma trận tương quan khá khó khăn, chúng ta sẽ dùng tới kiểm định Bartlett. Kiểm định này sẽ xem xét có mối tương quan xảy ra giữa các biến tham gia vào EFA hay không với giả thuyết Ho: Không có mối tương quan giữa các biến quan sát. Nếu sig kiểm định Bartlett nhỏ hơn 0.05, chúng ta bác bỏ Ho và kết luận các biến tham gia vào EFA có sự tương quan với nhau, ngược lại, nếu sig lớn hơn 0.05, chúng ta chấp nhận Ho và kết luận các biến quan sát không có sự tương quan với nhau, phân tích EFA là không phù hợp[1].
[1] Hair và cộng sự, Multivariate Data Analysis, Pearson, New Jersey, 2009.
2.3 Xác định số nhân tố được trích
Hair và cộng sự (2009)[1] cho rằng, việc thực hiện trích nhân tố cần kết hợp giữa lý thuyết nền và kết quả thực nghiệm của dữ liệu thu thập. Có nhiều phương pháp xác định số nhân tố được trích, hay còn gọi là chọn điểm dừng, vì chúng ta sẽ yêu cầu EFA dừng trích ở nhân tố thứ mấy như dựa vào eigenvalue, tổng phương sai trích, biểu đồ Scree Plot, dựa vào số nhân tố kỳ vọng muốn trích,… Thường các nhà nghiên cứu sẽ sử dụng kết hợp nhiều phương pháp để đánh giá để kết quả đem lại là tốt nhất. Dưới đây là 4 phương pháp phổ biến:
a. Tiêu chí Eigenvalue
Hair và cộng sự (2009) cho rằng chỉ những nhân tố có eigenvalue (hay còn gọi là latent roots) lớn hơn 1 mới được đánh giá là có ý nghĩa và được giữ lại.
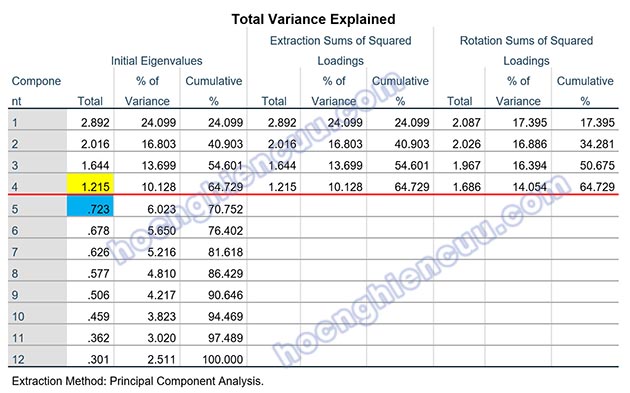
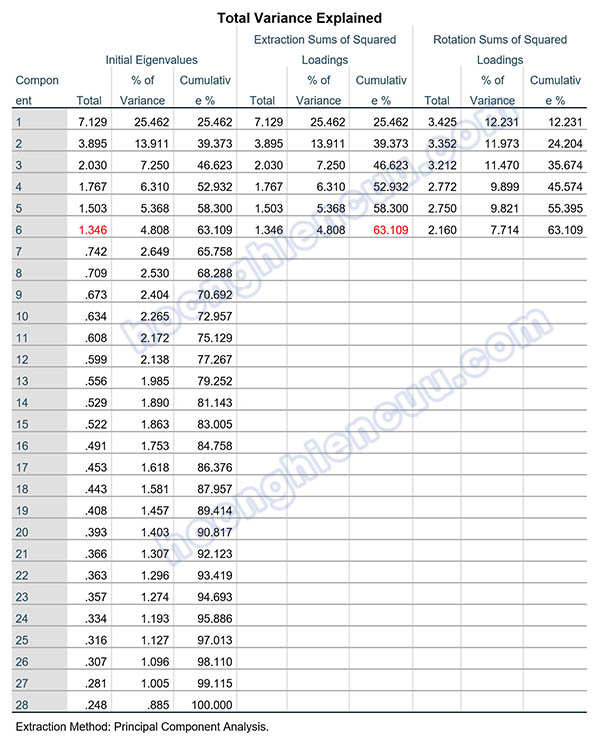
Eigenvalue thường nằm trong bảng Total Variance Explained. Cột Component luôn bằng với số lượng biến quan sát tham gia vào EFA. Cột Initial Eigenvalues biểu diễn giá trị eigenvalue ban đầu khi quá trình trích nhân tố chưa diễn ra. Ở cột Component có bao nhiêu nhân tố thì cột Initial Eigenvalues sẽ cung cấp giá trị tương ứng của toàn bộ các nhân tố này. Cột Extraction Sums of Squared Loadings là kết quả khi đã kết thúc quá trình trích nhân tố. Từ 12 nhân tố ban đầu, kết thúc quá trình trích chúng ta thu được 4 nhân tố. Cột Rotation Sums of Squared Loadings đưa ra kết quả các chỉ số sau khi kết thúc quá trình xoay nhân tố. Kết quả ở bảng trên cho thấy, giá trị eigenvalue tại nhân tố thứ 4 là 1.215 > 1, tại nhân tố thứ 5 là 0.723 < 1. Dựa theo tiêu chí eigenvalue ≥ 1, quá trình trích sẽ dừng tại nhân tố thứ 4, có 4 nhân tố được trích.
b. Tổng phương sai trích
Hướng tiếp cận của phương pháp này là số nhân tố được trích sẽ giải thích được một tỷ lệ phương sai nhất định của các biến quan sát. Theo Merenda (1997)[2], số nhân tố được trích cần đạt được phần trăm phương sai tích lũy (cumulative variance) ít nhất là 50%. Trong khi đó, Hair và cộng sự (2009) cho rằng, số nhân tố được trích giải thích được 60% tổng phương sai là tốt.
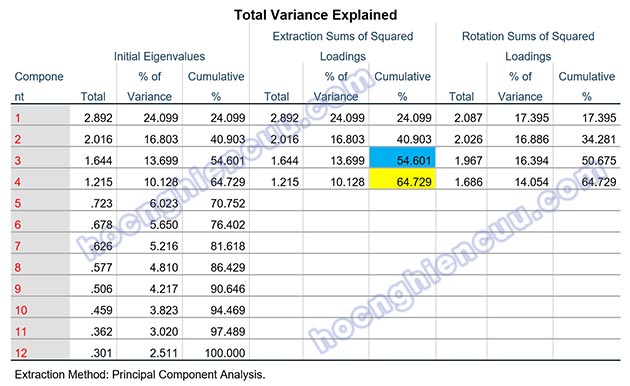
Trong bảng kết quả ở trên, từ nhân tố thứ ba trở đi, tổng phương sai trích được giải thích đạt mức trên 50%. Như vậy theo quan điểm của Merenda (1997) thì số nhân tố được trích nên từ 3 trở đi. Kết hợp với tiêu chí eigenvalue thì số nhân tố được trích tối ưu nên là 4 nhân tố tại phương sai tích lũy là 64.729% > 50%. Như vậy, 4 nhân tố được trích giải thích được (cô đọng được) 64.729% biến thiên dữ liệu của 12 biến quan sát tham gia vào EFA.
[1] Hair và cộng sự, Multivariate Data Analysis, Pearson, New Jersey, 2009.
[2] Merenda, A guide to the proper use of factor analysis in the conduct and reporting of research: Pitfalls to avoid. Measurement and Evaluation in Counseling and Development, 1997.
2.4 Hệ số tải nhân tố Factor Loading
Hệ số tải (hay còn gọi là trọng số nhân tố) có thể hiểu là mối tương quan giữa biến quan sát với nhân tố. Trị tuyệt đối hệ số tải của biến quan sát càng cao, nghĩa là tương quan giữa biến quan sát đó với nhân tố càng lớn và ngược lại. Trường hợp trong cùng một nhân tố, có sự xuất hiện của hệ số tải âm, nghĩa là biến quan sát đó tải ngược chiều so với phần lớn các biến quan sát còn lại trong nhân tố, biến quan sát này tương quan âm với các biến quan sát có hệ số tải dương trong nhân tố.
Với cỡ mẫu tối thiểu là 100, Hair và cộng sự (2009) cho rằng:
- Trị tuyệt đối Factor Loading ở mức 0.3 đến 0.4: cân nhắc là điều kiện tối thiểu để biến quan sát được giữ lại.
- Trị tuyệt đối Factor Loading ở mức từ 0.5 trở lên: mức tối ưu, các biến quan sát có ý nghĩa thống kê tốt.
Tuy nhiên, Hair và các cộng sự cũng cho rằng, việc chọn ngưỡng hệ số tải cũng nên xem xét đến cỡ mẫu, nhóm tác giả gợi ý bảng cỡ mẫu cần thiết tương ứng với mức hệ số tải nên lựa chọn như dưới đây:
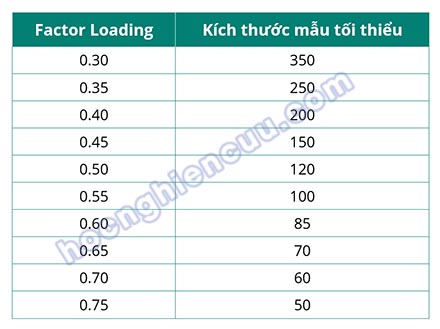
Các tác giả cho rằng bảng cỡ mẫu – hệ số tải tiêu chuẩn này được đưa ra tương đối cứng nhắc và nên được xem xét cùng với số lượng số lượng biến quan sát hay số nhân tố trích được trong phân tích EFA để đánh giá chất lượng biến quan sát. Với cỡ mẫu lớn hoặc số lượng biến tham gia vào EFA nhiều, hệ số tải nên lấy ở mức thấp; với những trường hợp số nhân tố trích được ở EFA lớn, ngưỡng hệ số tải nên lấy ở mức cao hơn.
- Mặc dù hệ số tải Factor Loading có trị tuyệt đối ở mức 0.3 đến 0.4 đạt điều kiện tối thiểu biến được chấp nhận biến có ý nghĩa. Tuy nhiên, mức 0.5 trở lên sẽ là ngưỡng tốt và phù hợp nhất khi đánh giá chất lượng biến quan sát trên thực nghiệm.
- Việc chọn hệ số tải cần xem xét kèm với cỡ mẫu, số lượng biến quan sát tham gia vào EFA và số nhân tố trích được ở EFA. Cỡ mẫu lớn, số lượng biến quan sát lớn, hệ số tải sẽ lấy ở ngưỡng thấp hơn; nếu số lượng nhân tố trích được lớn, hệ số tải cần lấy cao hơn.
3. Phân tích nhân tố khám phá EFA trên SPSS 26
Sử dụng tập dữ liệu thực hành có tên 350 – DLTH 1.sav của tài liệu SPSS 26 Phạm Lộc Blog, tương ứng với mô hình nghiên cứu và bảng câu hỏi khảo sát tại bài viết Bảng khảo sát các yếu tố ảnh hưởng đến sự hài lòng của nhân viên. Sau bước kiểm định Cronbach’s Alpha, biến LD7 đã được đánh giá là biến ít đóng góp vào thang đo Lãnh đạo và cần loại bỏ khỏi thang đo cho các bước phân tích tiếp theo. Chính vì vậy, ở bước đánh giá EFA (bước thực hiện sau Cronbach’s Alpha), chúng ta sẽ không đưa biến này vào phân tích. Với tính chất mô hình đơn giản, đã xác định rõ ràng biến độc lập, biến phụ thuộc. Chúng ta sẽ thực hiện phân tích nhân tố khám phá riêng cho biến độc lập và biến phụ thuộc.
Để thực hiện phân tích nhân tố khám phá trong SPSS 26, chúng ta vào Analyze > Dimension Reduction > Factor…
3.1 Phân tích EFA cho biến độc lập
Ngoại trừ biến LD7, đưa các biến quan sát độc lập còn lại vào mục Variables. Chú ý các tùy chọn bên phải, chúng ta sẽ đi qua lần lượt các tùy chọn này.
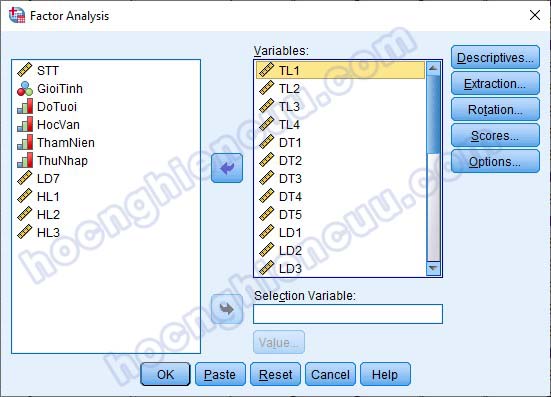
– Descriptives: Tích vào 3 mục: Initial solution, Coefficients, KMO and Barlett’s test of sphericity. Nhấp Continue để quay lại cửa sổ ban đầu.
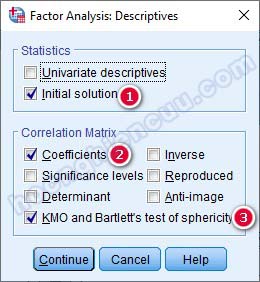
– Extraction: Đề tài nghiên cứu này là nghiên cứu lặp lại, đã có lý thuyết nền rõ ràng về các nhân tố, thang đo. Chúng ta sẽ sử dụng phép trích PCA (Principal Components hoặc Principal Components Analysis) với mục đích thu gọn số lượng biến quan sát về các nhân tố tóm tắt thông tin tốt nhất và tiêu chí trích Eigenvalue lớn hơn 1. Tích chọn vào các mục Scree Plot, Based on Eigenvalue.
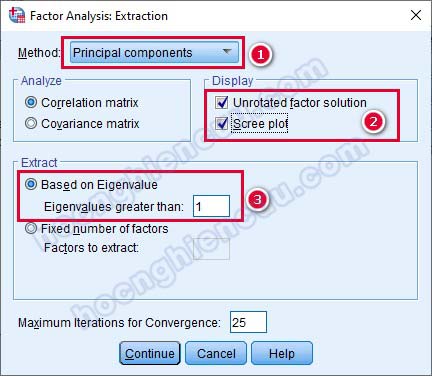
– Rotation: Mô hình nghiên cứu chỉ có biến độc lập và biến phụ thuộc, do vậy phép quay Varimax là phù hợp nhất. Nhấp Continue để quay lại cửa sổ ban đầu.
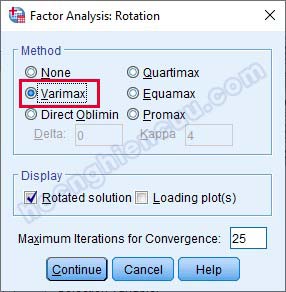
– Options: Tích vào Sorted by size để ma trận xoay sắp xếp thành từng cột dạng bậc thang để dễ đọc kết quả hơn, chúng ta có thể tích hoặc không tích, việc này không ảnh hưởng đến kết quả. Cần nhớ rằng, thứ tự các nhân tố trong kết quả ma trận xoay không phản ánh mức độ quan trọng của nhân tố đó. Với mục Suppress small coefficients, nếu không tích chọn, ma trận xoay sẽ hiển thị toàn bộ hệ số tải của mỗi biến quan sát ở từng nhân tố.
Trường hợp chỉ muốn ma trận xoay hiện lên những ô có hệ số tải từ 0.3, 0.4 hay 0.5 … trở lên, chúng ta sẽ tích vào Suppress small coefficients. Lúc này hàng Absolute value below sẽ sáng lên và cho phép nhập vào ngưỡng hệ số tải mà nếu hệ số tải dưới ngưỡng đó sẽ không hiển thị trong bảng ma trận xoay. Trong ví dụ thực hành này, để tiện cho việc theo dõi kết quả, tác giả muốn ma trận xoay chỉ hiển thị các ô có hệ số tải từ 0.3 trở lên nên sẽ nhập vào 0.3. Sau đó nhấp vào Continue để đóng cửa sổ.
Tại cửa sổ tiếp theo, chọn OK để xuất kết quả ra output.
Có khá nhiều bảng ở output, tất cả các bảng này đều đóng góp vào việc đánh giá kết quả phân tích EFA là tốt hay tệ. Tuy nhiên, ở đây tác giả tập trung vào ba bảng kết quả chính: KMO and Barlett’s Test, Total Variance Explained và Rotated Component Matrix, bởi sử dụng ba bảng này chúng ta đã có thể đánh giá được kết quả phân tích EFA phù hợp hay không phù hợp.

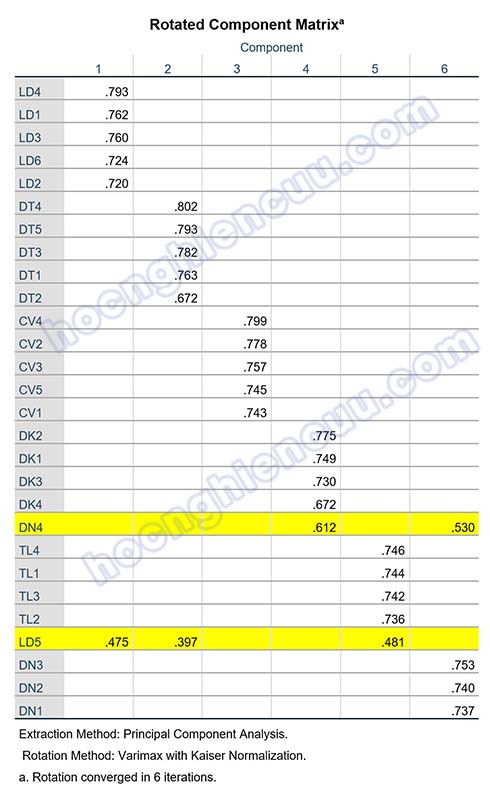
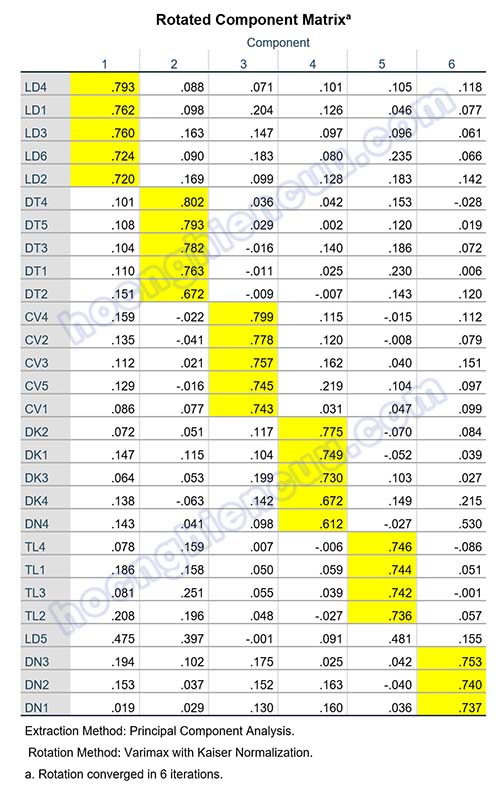
Kết quả lần EFA đầu tiên: KMO = 0.887 > 0.5, sig Bartlett’s Test = 0.000 < 0.05, như vậy phân tích nhân tố khám phá EFA là phù hợp. Có 6 nhân tố được trích với tiêu chí eigenvalue lớn hơn 1 với tổng phương sai tích lũy là 63.109%. Tác giả mong muốn chọn ra các biến quan sát chất lượng nên sẽ sử dụng ngưỡng hệ số tải là 0.5 thay vì chọn hệ số tải tương ứng theo cỡ mẫu. So sánh ngưỡng này với kết quả ở ma trận xoay, có hai biến xấu là DN4 và LD5 cần xem xét loại bỏ:
- Biến DN4 tải lên ở cả hai nhân tố là Component 4 và Component 6 với hệ số tải lần lượt là 0.612 và 0.530, mức chênh lệch hệ số tải bằng 0.612 – 0.530 = 0.082 < 0.2.
- Biến LD5 có hệ số tải ở tất cả các nhân tố đều nhỏ5.
Tác giả sử dụng phương thức loại một lượt các biến xấu trong một lần phân tích EFA. Từ 28 biến quan sát ở lần phân tích EFA thứ nhất, loại bỏ DN4 và LD5 và đưa 26 biến quan sát còn lại vào phân tích EFA lần thứ hai.

Hệ số KMO = 0.879 > 0.5, sig Barlett’s Test = 0.000 < 0.05, như vậy phân tích nhân tố là phù hợp.
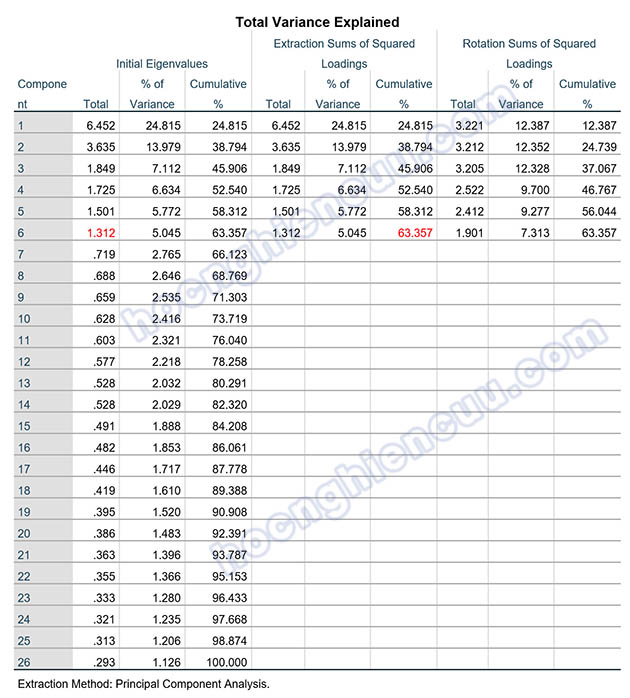
Có 6 nhân tố được trích dựa vào tiêu chí eigenvalue lớn hơn 1, như vậy 6 nhân tố này tóm tắt thông tin của 26 biến quan sát đưa vào EFA một cách tốt nhất. Tổng phương sai mà 6 nhân tố này trích được là 63.357% > 50%, như vậy, 6 nhân tố được trích giải thích được 63.357% biến thiên dữ liệu của 26 biến quan sát tham gia vào EFA.
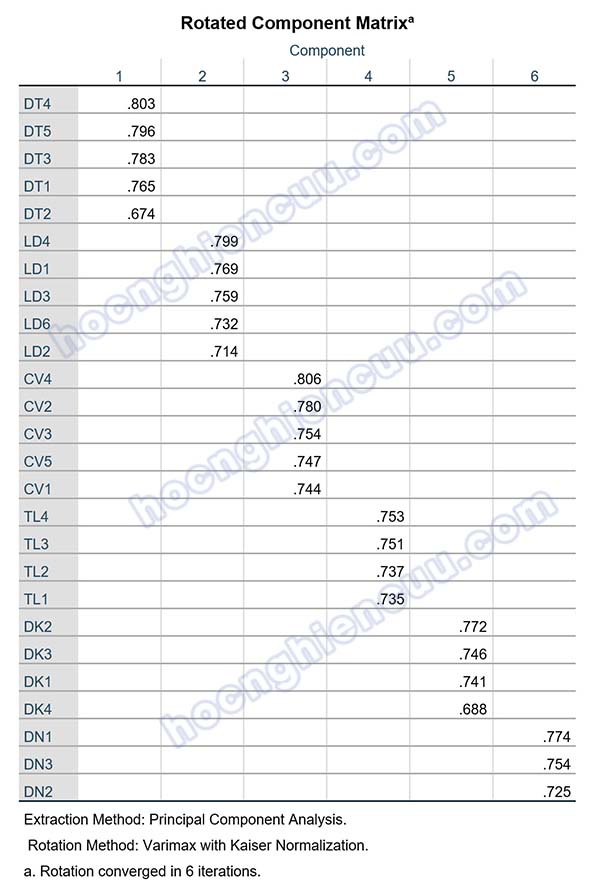
Kết quả ma trận xoay cho thấy, 26 biến quan sát được phân thành 6 nhân tố, tất cả các biến quan sát đều có hệ số tải nhân tố Factor Loading lớn hơn 0.5 và không còn các biến xấu.
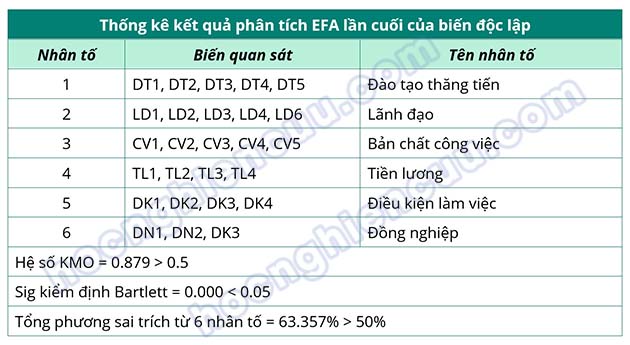
Như vậy, phân tích nhân tố khám phá EFA cho các biến độc lập được thực hiện hai lần. Lần thứ nhất, 28 biến quan sát được đưa vào phân tích, có 2 biến quan sát không đạt điều kiện là DN4 và LD5 được loại bỏ để thực hiện phân tích lại. Lần phân tích thứ hai (lần cuối cùng), 26 biến quan sát hội tụ và phân biệt thành 6 nhân tố gồm các biến quan sát được trình bày trong bảng bên dưới:
3.2 Phân tích EFA cho biến phụ thuộc
Tương tự với các thao tác trên biến độc lập, tiến hành thực hiện phân tích nhân tố khám phá EFA cho biến phụ thuộc.

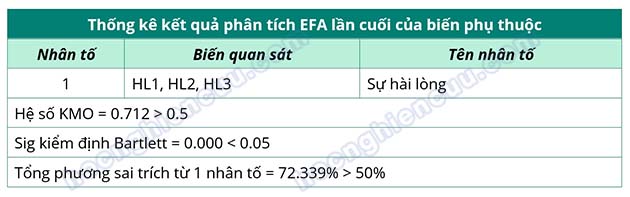
Hệ số KMO = 0.712 > 0.5, sig Barlett’s Test = 0.000 < 0.05, như vậy phân tích nhân tố là phù hợp.
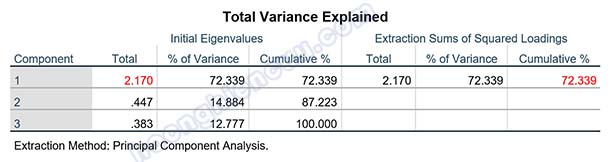
Kết quả phân tích cho thấy có 1 nhân tố được trích tại eigenvalue bằng 2.170 > 1. Nhân tố này giải thích được 72.339% biến thiên dữ liệu của 3 biến quan sát tham gia vào EFA.

Như đã đề cập trước đó ở mục 9.7. Nếu chỉ có một nhân tố được trích, ma trận xoay sẽ không hiển thị, chính vì vậy chúng ta sẽ đánh giá kết quả qua bảng ma trận nhân tố chưa xoay. Kết quả cho thấy 3 biến quan sát hội tụ về 1 cột và tất cả các biến quan sát đều có hệ số tải nhân tố lớn hơn 0.5.
Lưu ý rằng, nếu sau bước phân tích nhân tố EFA, cấu trúc thang đo bị thay đổi so với thang đo gốc: hình thành nhân tố mới, nhân tố giảm biến quan sát, nhân tố tăng biến quan sát… Chúng ta nên thực hiện kiểm định độ tin cậy thang đo Cronbach’s Alpha để đánh giá lại các thang đo mới được hình thành sau EFA.