Phân phối chuẩn (Normal Distribution) được xem là một giả định nền tảng trong nhiều phương pháp kiểm định thống kê tham số. Khi giả định này không được đáp ứng, kết quả phân tích có thể bị sai lệch, làm giảm độ chính xác và độ tin cậy của các kết luận nghiên cứu. Vì vậy, việc đánh giá mức độ phù hợp của dữ liệu với phân phối chuẩn là một bước không thể thiếu trước khi tiến hành các phân tích thống kê ở mức độ chuyên sâu hơn.
Trong phần mềm SPSS, hai phép kiểm định thường được sử dụng để kiểm tra giả định phân phối chuẩn bao gồm kiểm định Shapiro-Wilk (S-W) và kiểm định Kolmogorov-Smirnov (K-S). Nội dung bài viết tập trung trình bày quy trình thực hiện, cách diễn giải kết quả và những điểm cần lưu ý khi áp dụng hai kiểm định này trong phân tích dữ liệu bằng SPSS.
1. Cơ chế của kiểm định Shapiro–Wilk và Kolmogorov–Smirnov
Theo Andy Field (2009), một phương pháp phổ biến để đánh giá liệu dữ liệu có tuân theo phân phối chuẩn hay không là so sánh phân phối của dữ liệu quan sát với một phân phối chuẩn lý thuyết tương ứng, tức là có cùng giá trị trung bình và độ lệch chuẩn. Hai kiểm định thống kê thường được sử dụng cho mục đích này là Kolmogorov–Smirnov (K–S) và Shapiro–Wilk.
Về bản chất, có thể hình dung rằng tồn tại một phân phối chuẩn tham chiếu, ký hiệu là A, và một phân phối của dữ liệu thực nghiệm cần kiểm tra, ký hiệu là B. Hai phân phối này được chuẩn hóa về cùng trung bình và độ lệch chuẩn nhằm đảm bảo khả năng so sánh trực tiếp. Nếu phân phối B xấp xỉ phân phối A thì dữ liệu có thể được xem là tuân theo phân phối chuẩn; ngược lại, nếu sự khác biệt giữa B và A đủ lớn thì giả định phân phối chuẩn không được thỏa mãn. Kolmogorov–Smirnov và Shapiro–Wilk chính là các kiểm định thống kê được thiết kế để lượng hóa mức độ khác biệt này.
- Trong trường hợp kết quả kiểm định không có ý nghĩa thống kê (giá trị sig > 0.05), có thể kết luận rằng dữ liệu không khác biệt đáng kể so với phân phối chuẩn và do đó được xem là phân phối chuẩn.
- Ngược lại, nếu kết quả kiểm định có ý nghĩa thống kê (sig < 0.05), dữ liệu được cho là khác biệt đáng kể so với phân phối chuẩn và không thỏa mãn giả định phân phối chuẩn.
Hai kiểm định này có ưu điểm là cung cấp một tiêu chí định lượng rõ ràng thông qua giá trị sig để đánh giá tính chuẩn của dữ liệu. Tuy nhiên, chúng cũng tồn tại những hạn chế nhất định. Cụ thể, khi cỡ mẫu lớn, chỉ cần một mức độ sai lệch rất nhỏ so với phân phối chuẩn lý thuyết cũng có thể dẫn đến kết quả sig < 0.05. Trong trường hợp này, kiểm định cho thấy dữ liệu không có phân phối chuẩn, mặc dù mức độ sai lệch đó có thể không đáng kể và không ảnh hưởng thực chất đến các phân tích thống kê tiếp theo.
Ví dụ, giả sử có dữ liệu về độ tuổi của 500 người và mục tiêu là kiểm tra giả định phân phối chuẩn. Khi thực hiện kiểm định Shapiro–Wilk, kết quả thu được là sig = 0.03 < 0.05, từ đó kết luận rằng dữ liệu không tuân theo phân phối chuẩn. Tuy nhiên, khi quan sát biểu đồ Q–Q plot hoặc Histogram, dữ liệu chỉ thể hiện sự lệch nhẹ và không xuất hiện các giá trị ngoại lai nghiêm trọng. Trong bối cảnh này, dữ liệu vẫn có thể được sử dụng cho các phân tích thống kê yêu cầu giả định phân phối chuẩn mà không gây ảnh hưởng đáng kể đến kết quả.
Andy Field (2009) nhấn mạnh rằng:
Đối với các mẫu có kích thước lớn, cả kiểm định Kolmogorov–Smirnov và Shapiro–Wilk đều rất nhạy, dễ cho ra kết quả có ý nghĩa thống kê ngay cả khi dữ liệu chỉ lệch nhẹ khỏi phân phối chuẩn. Do đó, không nên chỉ dựa duy nhất vào kết quả của hai kiểm định này. Việc đánh giá tính chuẩn của dữ liệu cần được kết hợp với các phương pháp khác như quan sát biểu đồ Histogram, biểu đồ P–P plot hoặc Q–Q plot, cũng như xem xét các chỉ số mô tả như độ lệch (skewness) và độ nhọn (kurtosis).
3. Kiểm định phân phối chuẩn bằng Shapiro-Wilk và Kolmogorov-Smirnov trong SPSS
3.1 Quy trình thực hiện kiểm định Shapiro-Wilk và Kolmogorov-Smirnov trong SPSS
Giả sử nghiên cứu sử dụng một bộ dữ liệu minh họa với cỡ mẫu N = 200, bao gồm ba biến định lượng cần được kiểm tra giả định phân phối chuẩn, cụ thể như sau:
-
Biến HaiLong: giá trị trung bình được tổng hợp từ các biến quan sát thành phần, đo lường mức độ hài lòng của đối tượng nghiên cứu bằng thang đo Likert 5 mức.
-
Biến DoTuoi: dữ liệu phản ánh độ tuổi của người trả lời, dao động trong khoảng từ 19 đến 40 tuổi.
-
Biến ThuNhap: dữ liệu thu nhập hằng tháng của người trả lời, được đo lường theo đơn vị triệu đồng Việt Nam.
Để tiến hành kiểm định phân phối chuẩn bằng hai phương pháp Shapiro-Wilk và Kolmogorov-Smirnov trong phần mềm SPSS, người nghiên cứu lần lượt chọn Analyze > Descriptive Statistics > Explore.
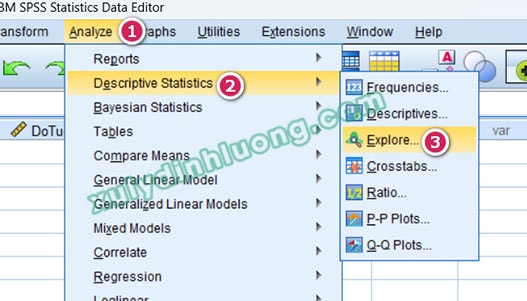
Trong hộp thoại Explore, các biến cần kiểm định được đưa vào ô Dependent List thông qua thao tác kéo thả hoặc sử dụng nút mũi tên. Trường hợp nghiên cứu yêu cầu đánh giá phân phối chuẩn theo từng nhóm đối tượng, biến phân nhóm sẽ được đưa vào ô Factor List, chẳng hạn như biến giới tính. Sau đó, người dùng tiếp tục chọn nút Plots ở phía bên phải hộp thoại.
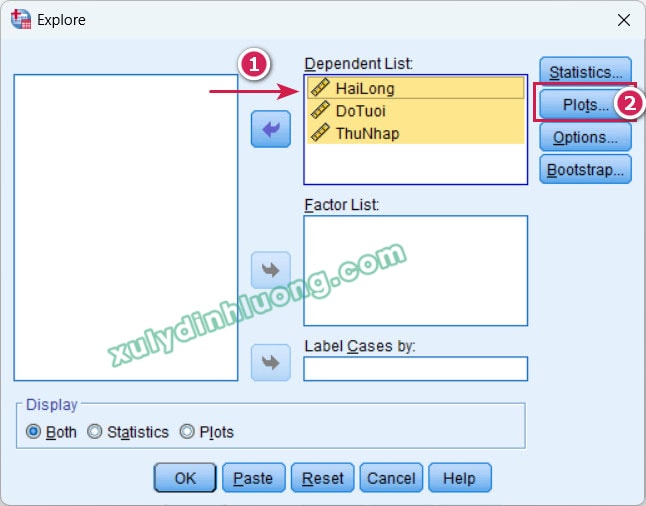
Trong hộp thoại này, chọn các mục Stem-and-leaf, Histogram, và đặc biệt là Normality plots with tests. Việc chọn mục Normality plots with tests là bắt buộc để SPSS thực hiện và hiển thị kết quả của các kiểm định Shapiro–Wilk và Kolmogorov–Smirnov. Sau đó, nhấp Continue.
Cuối cùng, trong hộp thoại Explore, nhấn OK để SPSS xuất kết quả ra cửa sổ Output. Kết quả thu được bao gồm nhiều bảng và đồ thị phục vụ cho việc đánh giá giả định phân phối chuẩn của dữ liệu. Tuy nhiên, trong phạm vi nội dung này, phân tích sẽ tập trung chủ yếu vào bảng Tests of Normality, là bảng thể hiện trực tiếp kết quả của hai phép kiểm định được sử dụng.
3.2 Diễn giải kết quả kiểm định Shapiro-Wilk và Kolmogorov-Smirnov trong SPSS
Trong bảng Tests of Normality của phần mềm SPSS, kết quả kiểm định phân phối chuẩn được trình bày thông qua hai phép kiểm định chính là Kolmogorov-Smirnov và Shapiro-Wilk, kèm theo các chỉ số thống kê cơ bản gồm:
- Statistic thể hiện giá trị thống kê của phép kiểm định;
- Df (Degrees of Freedom) là bậc tự do;
- Và Sig. (Asymp. Sig. (2-tailed)) biểu thị mức ý nghĩa thống kê.
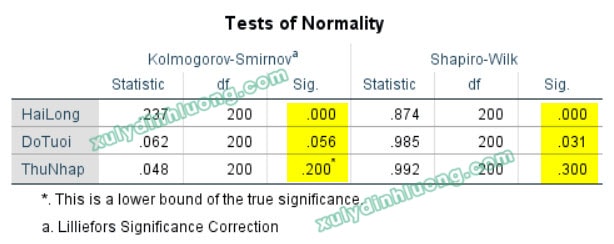
Đối với bộ dữ liệu đang xét, cỡ mẫu là 200 quan sát, lớn hơn 50, do đó có thể sử dụng đồng thời cả hai kiểm định Kolmogorov-Smirnov và Shapiro-Wilk để đánh giá giả định phân phối chuẩn của biến nghiên cứu.
Xét biến HaiLong
Kết quả kiểm định cho thấy
- Kolmogorov-Smirnov cho giá trị Sig. = 0.000, nhỏ hơn mức ý nghĩa 0.05.
- Tương tự, kiểm định Shapiro-Wilk cũng cho giá trị Sig. = 0.000, nhỏ hơn 0.05.
→ Như vậy, cả hai phép kiểm định đều bác bỏ giả thuyết dữ liệu tuân theo phân phối chuẩn, cho thấy biến HaiLong không có phân phối chuẩn trong tổng thể nghiên cứu.
Đối với biến DoTuoi
Kết quả kiểm định cho thấy:
- Kolmogorov-Smirnov cho giá trị Sig. = 0.056, lớn hơn mức ý nghĩa 0.05, cho thấy chưa đủ cơ sở để bác bỏ giả thuyết phân phối chuẩn.
- Ngược lại, kiểm định Shapiro-Wilk cho giá trị Sig. = 0.031, nhỏ hơn 0.05, chỉ ra rằng giả thuyết phân phối chuẩn bị bác bỏ.
→ Kết luận: Kết quả kiểm định Kolmogorov–Smirnov với Sig. = 0,056 (> 0,05) cho thấy dữ liệu có thể được xem là tuân theo phân phối chuẩn. Tuy nhiên, kiểm định Shapiro–Wilk cho kết quả Sig. = 0,031 (≤ 0,05), qua đó bác bỏ giả thuyết dữ liệu có phân phối chuẩn.
Trong bối cảnh kích thước mẫu tương đối lớn (N = 200), kiểm định Kolmogorov-Smirnov thường được xem là phù hợp hơn. Tuy nhiên, do giá trị Sig. của kiểm định này chỉ cao hơn ngưỡng 0.05 một mức rất nhỏ, việc đưa ra kết luận chỉ dựa trên kiểm định này là chưa thật sự thuyết phục. Vì vậy, cần tiến hành đánh giá bổ sung thông qua các phương pháp trực quan như biểu đồ Histogram có chồng đường cong phân phối chuẩn, Q-Q plot, P-P plot, đồng thời xem xét các chỉ số Skewness và Kurtosis để có cơ sở kết luận toàn diện hơn.
Trong trường hợp các biểu đồ và chỉ số Skewness/Kurtosis cho thấy dữ liệu tiệm cận với phân phối chuẩn, có thể chấp nhận rằng biến DoTuoi có phân phối gần chuẩn hoặc không sai lệch đáng kể so với phân phối chuẩn. Tuy nhiên, cần lưu ý rằng kiểm định Shapiro-Wilk đã cho kết quả không đạt chuẩn, đây được xem là một chỉ báo tương đối mạnh. Trên thực tế, khi có ít nhất một trong hai kiểm định cho thấy dữ liệu không tuân theo phân phối chuẩn, đặc biệt khi giá trị Sig. của Kolmogorov-Smirnov nằm sát ngưỡng 0.05, xu hướng chung là nghiêng về kết luận dữ liệu không có phân phối chuẩn.
Đối với biến ThuNhap
Kết quả kiểm định cho thấy:
Kolmogorov-Smirnov cho giá trị Sig. = 0.200
Kiểm định Shapiro-Wilk cho giá trị Sig. = 0.300
→ Đều lớn hơn mức ý nghĩa 0.05. Điều này cho thấy không có đủ bằng chứng thống kê để bác bỏ giả thuyết phân phối chuẩn. Do đó, có thể kết luận rằng biến ThuNhap tuân theo phân phối chuẩn.
Tóm lại, biến HaiLong không có phân phối chuẩn.
Biến DoTuoi có dấu hiệu không tuân theo phân phối chuẩn và cần được kiểm tra bổ sung thông qua các phương pháp trực quan và chỉ số Skewness/Kurtosis để khẳng định chắc chắn.
Trong khi đó, biến ThuNhap được xác định là có phân phối chuẩn.
Post Views:
50