Độ lệch chuẩn (Standard Deviation) là một chỉ tiêu thống kê dùng để phản ánh mức độ phân tán của các quan sát trong một tập dữ liệu xung quanh giá trị trung bình (Mean). Trong các phần mềm phân tích thống kê, độ lệch chuẩn thường được ký hiệu dưới dạng S.D hoặc Std. Deviation.
Trong quá trình thực hiện thống kê mô tả, độ lệch chuẩn thường được trình bày trong các bảng kết quả đầu ra. Khi đó, một vấn đề thường được đặt ra là giá trị độ lệch chuẩn ở mức nào thì được xem là chấp nhận được và ở mức nào thì không. Để trả lời câu hỏi này, cần hiểu rõ bản chất của chỉ số độ lệch chuẩn. Về mặt toán học, độ lệch chuẩn được xác định bằng căn bậc hai của phương sai, qua đó phản ánh mức độ dao động của các giá trị quan sát quanh giá trị trung bình theo chiều rộng hay hẹp. Khi độ lệch chuẩn có giá trị lớn, các điểm dữ liệu trên đồ thị phân tán sẽ nằm xa nhau và cách xa giá trị trung bình; ngược lại, khi độ lệch chuẩn nhỏ, các điểm dữ liệu có xu hướng tập trung gần đường trung bình hơn.
Xem thêm: Cách xử lý số liệu SPSS toàn tập mới nhất
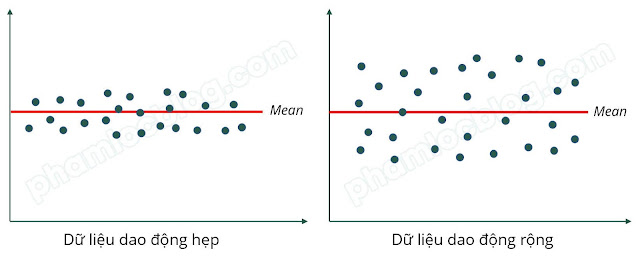
Tại thời điểm này, đại lượng CV được sử dụng như một chỉ số phản ánh mức độ biến thiên của dữ liệu, còn gọi là hệ số biến động (Coefficient of Variation).
CV được xác định theo công thức:
CV = (S.D/Mean) × 100%.
Trong đó:
- CV (Coefficient of Variation) là hệ số biến động,
- S.D (Standard Deviation) là độ lệch chuẩn,
- Mean là giá trị trung bình của tập dữ liệu.
Ví dụ, đối với môn Toán của 50 học sinh có điểm trung bình là 6.65 và độ lệch chuẩn là 1.112. Áp dụng công thức trên, hệ số biến động được tính như sau: CV = 1.112/6.65 × 100% = 16.7%.
Hiện nay, chưa tồn tại một ngưỡng đánh giá CV mang tính thống nhất, do chỉ số này chịu ảnh hưởng đáng kể bởi đặc điểm của từng lĩnh vực nghiên cứu cũng như mục tiêu phân tích cụ thể. Trong ấn phẩm Classification of the coefficients of variation of parameters evaluated in Japanese quail experiments (2014), đăng trên Braz. J. Poult, tác giả có đề cập đến hệ thống phân loại CV do Gomes (2000) đề xuất trong bối cảnh nghiên cứu thực nghiệm trên chim cút Nhật Bản, bao gồm:
- CV < 10%: mức thấp
- 10% ≤ CV < 20%: mức trung bình
- 20% ≤ CV < 30%: mức cao
- CV ≥ 30%: mức rất cao
– Trường hợp CV có giá trị cao cho thấy dữ liệu có mức độ dao động lớn, phản ánh sự khác biệt đáng kể giữa các giá trị quan sát. Điều này đồng nghĩa với việc các câu trả lời của đáp viên tại biến nghiên cứu có sự phân tán mạnh. Chẳng hạn, với một câu hỏi đo lường theo thang Likert 1–5, có nhiều người lựa chọn các mức thấp như 1, 2 và đồng thời nhiều người lựa chọn các mức cao như 4, 5. Sự khác biệt lớn giữa các mức đánh giá làm cho độ lệch chuẩn tăng cao.
– Ngược lại, khi CV có giá trị thấp, độ lệch chuẩn nhỏ hơn đáng kể so với giá trị trung bình, cho thấy mức độ dao động của dữ liệu yếu và các câu trả lời của đáp viên tương đối đồng nhất. Ví dụ, với một câu hỏi sử dụng thang Likert 1–5, phần lớn đáp viên có xu hướng lựa chọn các mức điểm tập trung quanh 1, 2, 3 hoặc quanh 3, 4 hay 4, 5. Trong trường hợp này, mức chênh lệch giữa các đánh giá là không lớn, phản ánh tính ổn định tương đối của dữ liệu.
Quay lại vấn đề: độ lệch chuẩn ở mức nào được xem là chấp nhận được? Trên thực tế, không tồn tại một ngưỡng cố định để kết luận độ lệch chuẩn là chấp nhận hay không chấp nhận. Nói cách khác, độ lệch chuẩn không mang ý nghĩa tốt hay xấu một cách tuyệt đối. Chỉ số này phản ánh mức độ phân tán của dữ liệu quanh giá trị trung bình, tức cho biết dữ liệu tập trung hay dàn trải. Việc đánh giá độ lệch chuẩn là phù hợp hay không phụ thuộc hoàn toàn vào mục tiêu nghiên cứu và kỳ vọng của nhà nghiên cứu. Có thể minh họa điều này thông qua một câu hỏi được đo lường bằng thang đo Likert 5 mức độ đồng ý.
– Trong trường hợp câu hỏi đó được sử dụng để đo lường mức độ ổn định trong quan điểm của người trả lời, nhà nghiên cứu thường kỳ vọng các đáp án tập trung nhiều vào các mức 3, 4, 5 (nhóm đồng ý), thay vì phân bố đều ở cả 5 mức từ 1 đến 5. Khi cùng một câu hỏi được đặt ra cho cùng một nhóm đối tượng có đặc điểm nhân khẩu học tương đối đồng nhất, nhưng có người cho điểm rất cao trong khi người khác lại cho điểm rất thấp, sự phân tán lớn này sẽ làm cho độ lệch chuẩn tăng cao. Nếu kết quả này đi ngược lại với kỳ vọng nghiên cứu hoặc nền tảng lý thuyết đã đặt ra, thì độ lệch chuẩn cao trong bối cảnh này được xem là không phù hợp.
– Ngược lại, với cùng câu hỏi đó, nếu mục tiêu nghiên cứu là xem xét sự khác biệt trong hành vi hoặc thái độ của đáp viên dựa trên các đặc điểm nhân khẩu học khác nhau, nhà nghiên cứu có thể kỳ vọng mức độ chênh lệch lớn giữa các nhóm. Kỳ vọng này thường dựa trên cơ sở lý thuyết hoặc các nghiên cứu định tính đã được thực hiện trước đó. Tuy nhiên, nếu kết quả thu được cho thấy các đáp án chủ yếu tập trung vào cùng một nhánh, chẳng hạn đều ở mức 3, 4, 5 và mức điểm khá đồng đều, thì độ lệch chuẩn sẽ thấp. Trong trường hợp này, độ lệch chuẩn thấp lại không đáp ứng được kỳ vọng nghiên cứu và do đó được xem là không phù hợp.
Trong quá trình phân tích dữ liệu bằng SPSS, nếu dữ liệu gặp vấn đề như phân bố không phù hợp hoặc vi phạm các giả định kiểm định thống kê, nhà nghiên cứu có thể tham khảo các dịch vụ hỗ trợ SPSS của Phạm Lộc Blog nhằm tối ưu hóa thời gian xử lý và nâng cao chất lượng kết quả nghiên cứu.
—–
Tài liệu tham khảo:
Braz. J. Poult, Classification of the coefficients of variation of parameters evaluated in Japanese quail experiments, 2014, Brazilian Journal of Poultry Science.