Khi diễn giải kết quả phân tích bằng SMARTPLS 4, cần tuân thủ nghiêm ngặt quy trình gồm hai giai đoạn bắt buộc theo trình tự logic.
Giai đoạn 1 là đánh giá mô hình đo lường (Measurement model), nhằm xem xét chất lượng của thang đo thông qua các tiêu chí chủ yếu như độ tin cậy, giá trị hội tụ và giá trị phân biệt.
Giai đoạn 2 là đánh giá mô hình cấu trúc (Structural model), tập trung phân tích ý nghĩa thống kê của các mối quan hệ giữa các biến, mức độ giải thích của mô hình, hiện tượng đa cộng tuyến, cũng như các tác động gián tiếp, tác động điều tiết và phân tích MGA.
Hai giai đoạn này phải được thực hiện tuần tự và không thể đảo ngược. Chỉ khi mô hình đo lường đạt yêu cầu thì mới có cơ sở khoa học để tiếp tục đánh giá mô hình cấu trúc, bởi nếu thang đo không đảm bảo chất lượng đo lường thì các kết luận rút ra từ mô hình cấu trúc sẽ không có giá trị.
I. Cách đọc kết quả SMARTPLS 4: Mô hình đo lường (Measurement Model)
Giai đoạn này tập trung đánh giá mức độ tin cậy và giá trị của thang đo, bao gồm giá trị hội tụ và giá trị phân biệt, nhằm kiểm định mức độ phù hợp của các công cụ đo lường được sử dụng để đại diện cho các khái niệm hay biến tiềm ẩn trong mô hình nghiên cứu. Mục tiêu cốt lõi của bước này là xác nhận rằng tập hợp các biến quan sát được xây dựng có khả năng phản ánh chính xác và nhất quán nhân tố mà chúng đại diện. Những biến quan sát hoặc thang đo không đạt yêu cầu về mặt thống kê và độ tin cậy sẽ được xem xét loại bỏ trước khi tiến hành phân tích mô hình cấu trúc.
Trong phương pháp PLS-SEM, các cấu trúc nhân tố có thể được đo lường thông qua hai dạng thang đo cơ bản là thang đo phản ánh (reflective) và thang đo tạo thành (formative). Việc trình bày và phân tích đồng thời cả hai loại thang đo trong cùng một nghiên cứu tổng hợp có thể làm giảm tính mạch lạc và gây khó khăn trong việc xác định trọng tâm phân tích.
Do thang đo phản ánh được sử dụng phổ biến trong phần lớn các nghiên cứu thực nghiệm hiện nay, nội dung đánh giá mô hình đo lường trong phần này chỉ tập trung vào cách tiếp cận đối với thang đo reflective.
Trường hợp nghiên cứu sử dụng thang đo formative và cần hướng dẫn chi tiết về quy trình đánh giá, người đọc có thể tham khảo các tài liệu chuyên biệt được trình bày riêng cho loại thang đo này.
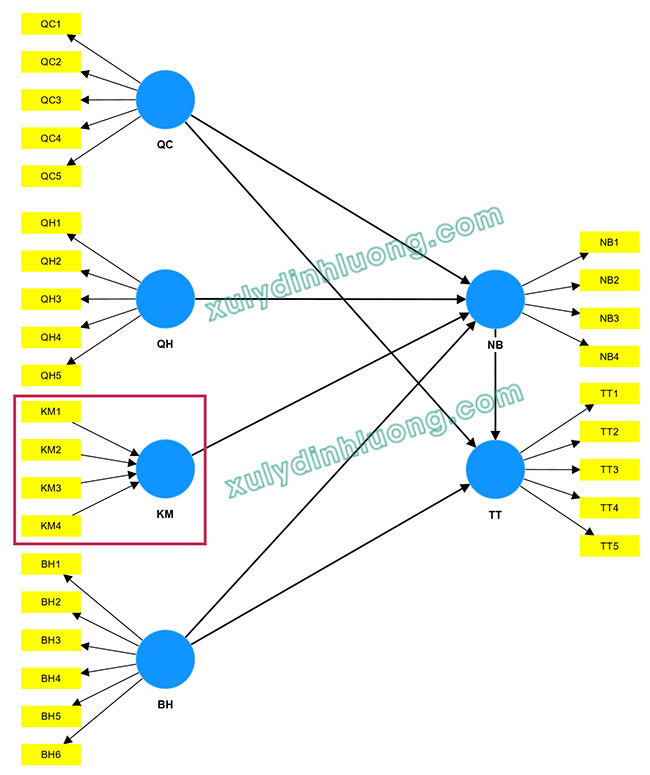
Giả sử một mô hình nghiên cứu được xây dựng như sau:
1. Đánh giá độ tin cậy của biến quan sát (indicator reliability)
Đánh giá độ tin cậy của các biến quan sát (chỉ báo) được thực hiện nhằm xem xét mức độ mà các biến này phản ánh chính xác và nhất quán khái niệm tiềm ẩn trong từng cấu trúc nhân tố. Thông qua bước đánh giá này, có thể nhận diện những biến quan sát có khả năng giải thích thấp đối với biến tiềm ẩn, từ đó loại bỏ các chỉ báo không phù hợp và chỉ giữ lại những biến đại diện tốt nhất cho cấu trúc nghiên cứu.
Ngưỡng đánh giá được áp dụng như sau:
– Hệ số tải ngoài ≥ 0.7 cho thấy biến quan sát đạt chất lượng tốt và có độ tin cậy cao.
– Hệ số tải ngoài < 0.4 cho thấy biến quan sát không đáp ứng yêu cầu và nên được loại bỏ.
– Trường hợp hệ số tải ngoài nằm trong khoảng từ 0.4 đến < 0.7 cần được cân nhắc kỹ lưỡng, do đây là ngưỡng còn nhiều tranh luận và phụ thuộc vào quan điểm của nhà nghiên cứu
- Cụ thể, nếu độ tin cậy tổng hợp (CR) hoặc phương sai trích trung bình (AVE) chưa đạt chuẩn, việc loại bỏ biến quan sát có thể được xem xét nếu điều này giúp các chỉ số CR hoặc AVE cải thiện và đạt ngưỡng chấp nhận.
- Ngược lại, trong trường hợp CR và AVE đã đạt yêu cầu, biến quan sát vẫn có thể được giữ lại nếu nó có ý nghĩa quan trọng về mặt lý thuyết.
Trong thực tiễn phân tích, kết quả hệ số tải ngoài được quan sát thông qua chức năng Outer loadings sau khi chạy thuật toán PLS-SEM. Việc đánh giá mô hình đo lường được thực hiện bằng phần mềm SmartPLS 4.
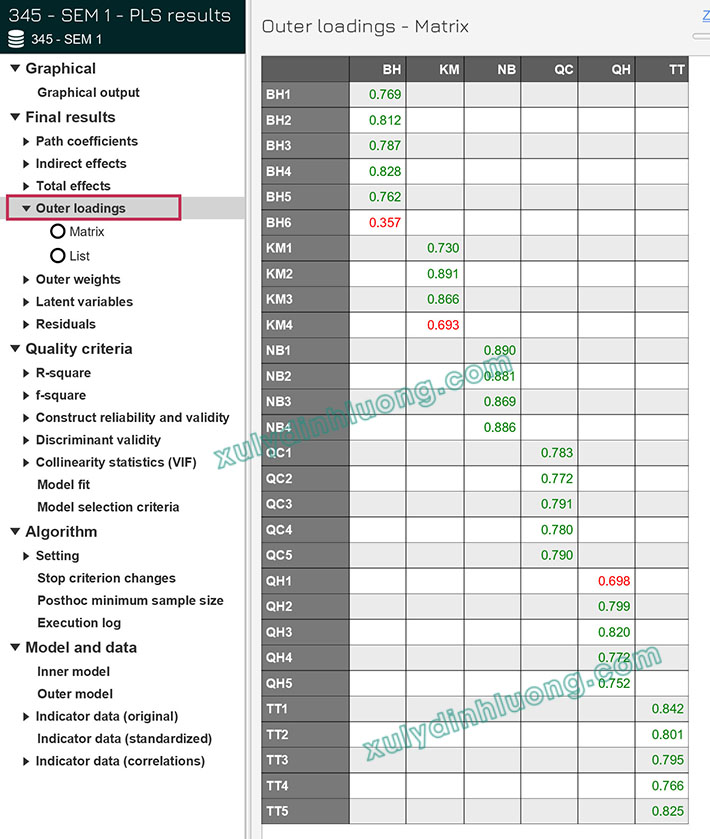
Trong nghiên cứu này, tác giả lựa chọn tiêu chí loại bỏ hoàn toàn các biến quan sát có hệ số outer loading dưới 0.7, chỉ giữ lại những biến có hệ số từ 0.7 trở lên nhằm đảm bảo độ tin cậy của mô hình đo lường. Kết quả phân tích cho thấy các biến BH6 và QH1 có hệ số outer loading nhỏ hơn 0.7, do đó hai biến này được loại bỏ khỏi sơ đồ mô hình và tiến hành phân tích lại ở lần thứ hai.
2. Độ tin cậy thang đo (Scale Reliability)
SMARTPLS cung cấp ba chỉ số nhằm đánh giá độ tin cậy của thang đo hay mức độ nhất quán nội bộ, bao gồm Cronbach’s alpha, Composite reliability rho_a và Composite reliability rho_c.
Theo Hair và cộng sự (2022), Cronbach’s Alpha có xu hướng đánh giá thấp độ tin cậy của thang đo, trong khi Composite Reliability rho_c lại thường cho kết quả đánh giá cao hơn mức độ tin cậy thực tế. Do đó, độ tin cậy thực sự của một cấu trúc tiềm ẩn thường được xem là nằm trong khoảng giữa hai giá trị này.
Trong bối cảnh đó, chỉ số rho_a (Dillon–Goldstein’s rho) được xem là phản ánh độ tin cậy một cách chính xác hơn, do giá trị của nó thường nằm giữa Cronbach’s Alpha và rho_c, qua đó thể hiện phù hợp hơn mức độ nhất quán nội tại của thang đo (Hair et al., 2022). Đây cũng là điểm khác biệt quan trọng giữa Composite Reliability rho_c và Composite Reliability rho_a, khi rho_a thường được ưu tiên sử dụng như một thước đo đáng tin cậy hơn. Tuy nhiên, trong một số trường hợp, Composite Reliability rho_a có thể nhạy cảm với dữ liệu và cho ra giá trị vượt quá ngưỡng 1.
Xem thêm: Khác biệt Composite Reliability rho_c và rho_a trong SMARTPLS
Ngưỡng đánh giá chung đối với cả ba chỉ số độ tin cậy được đề xuất như sau:
- Giá trị từ 0.70 trở lên cho thấy thang đo đạt độ tin cậy tốt;
- Giá trị từ 0.60 trở lên có thể được chấp nhận trong các nghiên cứu mang tính khám phá;
- Giá trị lớn hơn 0.95 cho thấy nguy cơ trùng lặp giữa các biến quan sát;
- Trong khi các giá trị mang dấu âm hoặc vượt quá 1 là dấu hiệu cho thấy dữ liệu có khả năng gặp vấn đề.
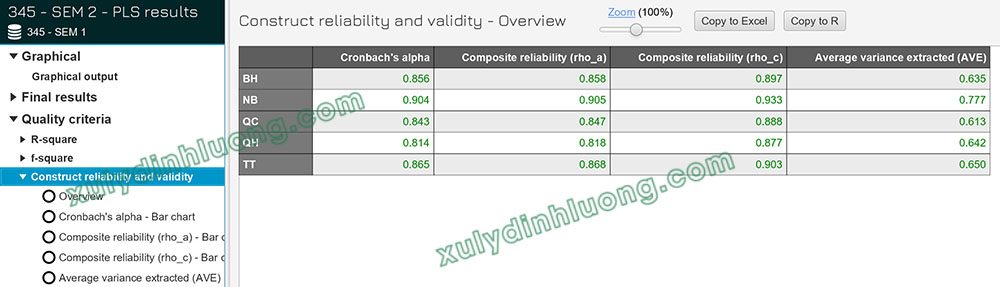
Ví dụ: Dựa trên kết quả phân tích PLS-SEM algorithm trong SMARTPLS 4, tại mục Construct reliability and validity,
Kết quả cho thấy toàn bộ các cấu trúc nhân tố đều đạt độ tin cậy tốt khi Cronbach’s Alpha và Composite Reliability (rho_c) đều lớn hơn ngưỡng chấp nhận 0.7. Điều này khẳng định rằng các biến quan sát trong từng thang đo có mức độ nhất quán nội tại cao và cùng đo lường một khái niệm tiềm ẩn.
Trong trường hợp xuất hiện cấu trúc nhân tố không đáp ứng ngưỡng độ tin cậy tối thiểu, quy trình xử lý được thực hiện bằng cách loại dần các biến quan sát có hệ số tải ngoài thấp nhất trong thang đo, sau đó tiến hành chạy lại phân tích PLS-SEM để đánh giá lại độ tin cậy. Quá trình này được lặp lại nhiều lần cho đến khi cấu trúc nhân tố đạt được mức độ tin cậy yêu cầu thì dừng.
Nếu sau khi loại biến, thang đo vẫn còn tối thiểu hai biến quan sát và đạt ngưỡng độ tin cậy, có thể kết luận rằng cấu trúc nhân tố đạt độ tin cậy. Ngược lại, nếu số biến quan sát giảm xuống còn hai mà thang đo vẫn không đạt ngưỡng độ tin cậy, cấu trúc nhân tố đó được xem là không đảm bảo độ tin cậy và cần được cân nhắc loại bỏ khỏi mô hình. Trong một số trường hợp đặc biệt, thang đo chỉ gồm một biến quan sát có thể được chấp nhận, tuy nhiên cách tiếp cận này chỉ nên áp dụng một cách rất hạn chế.
3. Tính hội tụ của thang đo (Convergent Validity)
Việc đánh giá tính hội tụ của thang đo trong SMARTPLS được thực hiện thông qua chỉ số phương sai trích trung bình AVE (Average Variance Extracted). Theo Hock và Ringle (2010), một thang đo được xem là đạt giá trị hội tụ khi AVE có giá trị từ 0.50 trở lên. Ngưỡng 0.50 hàm ý rằng biến tiềm ẩn giải thích được ít nhất 50% phương sai của các biến quan sát tương ứng.
Tiêu chí đánh giá:
AVE ≥ 0.50: thang đo đạt tính hội tụ.
Trong trường hợp dữ liệu thu thập có chất lượng chưa đảm bảo, dẫn đến vi phạm các yêu cầu về độ tin cậy, tính hội tụ hoặc tính phân biệt, hoặc số lượng biến quan sát bị loại bỏ quá nhiều, người nghiên cứu có thể cân nhắc tìm đến các dịch vụ hỗ trợ phân tích SMARTPLS chuyên nghiệp để được tư vấn và nâng cao chất lượng kết quả nghiên cứu.
Ví dụ, từ kết quả chạy thuật toán PLS-SEM, người nghiên cứu truy cập vào mục Construct Reliability and Validity và quan sát cột AVE ở cuối bảng kết quả của mô hình đo lường trên SMARTPLS 4.
Kết quả phân tích cho thấy các cấu trúc nhân tố đều đạt yêu cầu về tính hội tụ, thể hiện ở việc giá trị AVE của các thang đo đều lớn hơn hoặc bằng 0.50.
Trong trường hợp một thang đo có AVE nhỏ hơn 0.50, cần tiến hành loại bỏ lần lượt các biến quan sát có hệ số tải ngoài (outer loading) thấp nhất nhằm cải thiện giá trị AVE. Quá trình này được thực hiện lặp lại cho đến khi AVE của thang đo đạt ngưỡng chấp nhận.
Sau khi loại biến, nếu thang đo vẫn còn tối thiểu hai biến quan sát và AVE đạt từ 0.50 trở lên, có thể kết luận thang đo đáp ứng yêu cầu về tính hội tụ.
Ngược lại, nếu thang đo chỉ còn hai biến quan sát nhưng AVE vẫn thấp hơn 0.50, thang đo được xem là không đạt tính hội tụ và cần loại bỏ toàn bộ nhân tố này khỏi mô hình nghiên cứu.
4. Tính phân biệt thang đo (Discriminant Validity)
Tính phân biệt được sử dụng để xác nhận rằng mỗi cấu trúc tiềm ẩn trong mô hình nghiên cứu đại diện cho một khái niệm riêng biệt và không trùng lặp với các cấu trúc khác. Một thang đo được xem là đạt tính phân biệt khi nó đo lường một khái niệm duy nhất và không bị chồng lấn về nội dung hay ý nghĩa với các thang đo còn lại.
Trường hợp tính phân biệt không được đảm bảo, các cấu trúc trong mô hình không còn mang tính độc lập, từ đó có thể dẫn đến sai lệch trong ước lượng các mối quan hệ cấu trúc và làm suy giảm giá trị giải thích cũng như độ tin cậy của kết quả nghiên cứu.
Trong phần mềm SmartPLS 4, tính phân biệt của thang đo thường được đánh giá thông qua hai phương pháp chính:
a. Tiêu chí Fornell và Larcker
Theo tiêu chí này, một cấu trúc được xem là đạt tính phân biệt khi căn bậc hai của giá trị phương sai trích trung bình (AVE) của cấu trúc đó lớn hơn toàn bộ các hệ số tương quan giữa cấu trúc này với các cấu trúc khác trong mô hình. Cách tiếp cận này cho phép kiểm tra mức độ mà một cấu trúc chia sẻ phương sai với các chỉ báo của chính nó so với phương sai chia sẻ với các cấu trúc khác.
Ngưỡng đánh giá được xác định như sau:
Căn bậc hai AVE lớn hơn tất cả các hệ số tương quan trong cùng hàng hoặc cột cho thấy thang đo đạt tính phân biệt.
Ngược lại, nếu tồn tại hệ số tương quan lớn hơn hoặc bằng căn bậc hai AVE thì tính phân biệt bị vi phạm.
Trong SmartPLS 4, người nghiên cứu có thể xem kết quả này bằng cách chạy thuật toán PLS-SEM, chọn mục Discriminant Validity và truy cập bảng Fornell–Larcker Criterion.
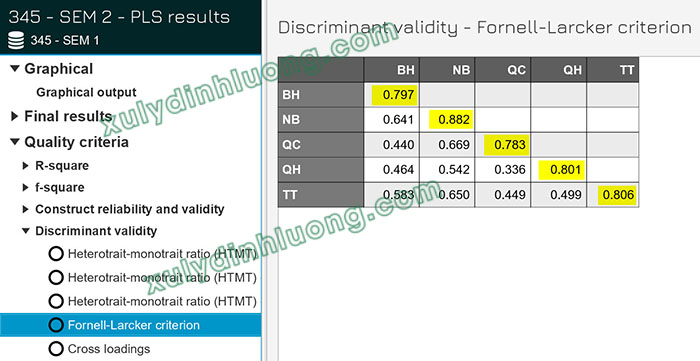
Trong bảng kết quả, các giá trị được đánh dấu (thường nằm trên đường chéo chính) biểu thị căn bậc hai của AVE của từng nhân tố, ví dụ như BH, NB hay QC. Các giá trị còn lại trong bảng thể hiện hệ số tương quan giữa các nhân tố.
Khi diễn giải kết quả Fornell–Larcker, cần so sánh hệ số tương quan giữa hai nhân tố với căn bậc hai AVE của từng nhân tố trong cặp đó. Nếu hệ số tương quan nhỏ hơn cả hai giá trị căn bậc hai AVE, thì hai nhân tố được xem là có tính phân biệt. Ngược lại, nếu hệ số tương quan lớn hơn hoặc bằng một trong hai giá trị căn bậc hai AVE thì cặp nhân tố đó vi phạm tính phân biệt.
Ví dụ, giả sử hệ số tương quan giữa BH và NB là 0.641, trong khi căn bậc hai AVE của BH là 0.797 và của NB là 0.882. Do 0.641 nhỏ hơn cả 0.797 và 0.882, có thể kết luận rằng hai nhân tố BH và NB đạt tính phân biệt.
Kết quả phân tích thực nghiệm cho thấy tất cả các nhân tố trong mô hình đều đáp ứng tiêu chí Fornell–Larcker, vì không tồn tại cặp nhân tố nào có hệ số tương quan vượt quá các giá trị căn bậc hai AVE tương ứng.
b. Chỉ số HTMT (Heterotrait–Monotrait Ratio)
Henseler và cộng sự (2015) đã chỉ ra những hạn chế nhất định của các phương pháp đánh giá tính phân biệt truyền thống, đồng thời đề xuất sử dụng chỉ số heterotrait–monotrait ratio (HTMT) như một tiêu chí thay thế có độ chính xác cao hơn. HTMT đo lường tỷ lệ giữa tương quan trung bình của các biến quan sát thuộc hai nhân tố khác nhau và tương quan trung bình của các biến trong cùng một nhân tố. Xem thêm tại Đánh giá tính phân biệt thang đo bằng HTMT trong SMARTPLS.
Về mặt lý thuyết, nếu hai nhân tố thực sự khác biệt, giá trị HTMT giữa chúng phải ở mức thấp.
Các ngưỡng đánh giá HTMT thường được sử dụng bao gồm:
- HTMT nhỏ hơn 0.85 cho thấy tính phân biệt rõ ràng;
- HTMT nhỏ hơn 0.90 vẫn được chấp nhận;
- HTMT lớn hơn hoặc bằng 0.90 phản ánh sự vi phạm nghiêm trọng tính phân biệt.
Trong SmartPLS 4, chỉ số này có thể được truy xuất bằng cách chạy thuật toán PLS-SEM, chọn Discriminant Validity và tiếp tục chọn Heterotrait–Monotrait Ratio (HTMT) Matrix.
Kết quả từ ví dụ minh họa cho thấy toàn bộ các giá trị HTMT đều nhỏ hơn 0.90, do đó có thể kết luận rằng các thang đo trong mô hình đảm bảo tính phân biệt.
Trong trường hợp tính phân biệt bị vi phạm:
- Trước hết cần kiểm tra giá trị HTMT để xác định mức độ vi phạm, trong đó HTMT lớn hơn hoặc bằng 0.90 cho thấy hai nhân tố không đủ khác biệt về mặt khái niệm.
- Tiếp theo, cần xem xét bảng cross-loading nhằm xác định các biến quan sát gây nhiễu, đặc biệt là những biến có hệ số tải ngoài thấp hoặc có hệ số tải lên nhân tố khác gần tương đương với nhân tố gốc.
- Các biến quan sát có vấn đề nên được loại bỏ dần và mô hình cần được chạy lại, đồng thời kiểm tra lại các chỉ số HTMT và Fornell–Larcker sau mỗi lần điều chỉnh.
- Nếu việc loại biến không cải thiện được tính phân biệt, cần xem xét lại nội dung thang đo, bởi khả năng cao các nhân tố đang đo lường những khía cạnh quá tương đồng.
- Trong trường hợp lý thuyết cho phép và bản chất các nhân tố thực sự phản ánh cùng một khái niệm, việc gộp các nhân tố có thể được cân nhắc.
- Ngược lại, nếu cần duy trì sự tách biệt giữa các nhân tố, mô hình bậc cao có thể được sử dụng để làm giảm mức độ tương quan giữa các nhân tố con.
- Khi tất cả các biện pháp trên đều không mang lại hiệu quả, mô hình lý thuyết hoặc cấu trúc thang đo ban đầu cần được xem xét và điều chỉnh lại một cách toàn diện.
II. Cách đọc kết quả SMARTPLS 4: Mô hình cấu trúc (Structural Model – SEM)
Sau khi mô hình đo lường (measurement model) đáp ứng đầy đủ các tiêu chí về độ tin cậy, giá trị hội tụ và giá trị phân biệt, bước tiếp theo trong phân tích PLS-SEM là đánh giá mô hình cấu trúc. Giai đoạn này nhằm kiểm định các mối quan hệ nhân quả giữa các biến tiềm ẩn, xác định mức độ ủng hộ của dữ liệu đối với các giả thuyết nghiên cứu, đồng thời đánh giá khả năng giải thích tổng thể của mô hình.
1. Đánh giá hiện tượng cộng tuyến giữa các biến tiềm ẩn (Inner VIF)
Trong đánh giá mô hình cấu trúc, cần xem xét hiện tượng cộng tuyến giữa các biến tiềm ẩn đóng vai trò biến độc lập. Trong bối cảnh PLS-SEM, biến độc lập được hiểu là các biến có mũi tên hướng đến một biến khác, tức là các biến dự báo trong mối quan hệ nhân quả. Ngược lại, biến nhận mũi tên tác động được xem là biến phụ thuộc.
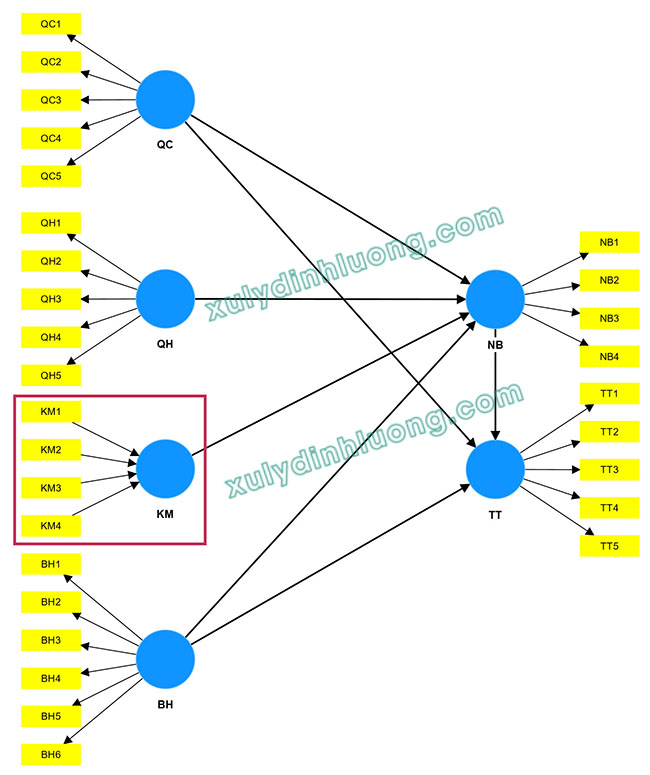
Trong mô hình minh họa:
- NB là biến phụ thuộc và chịu tác động từ bốn biến độc lập gồm QC, QH, KM và BH.
- Đồng thời, TT là biến phụ thuộc và chịu ảnh hưởng từ ba biến độc lập là QC, BH và NB.
Xem thêm: Mua phần mềm SMARTPLS 4 Pro full bản quyền giá tốt
Việc đánh giá cộng tuyến được thực hiện riêng cho từng tập hợp biến độc lập tác động lên cùng một biến phụ thuộc, bao gồm:
- (i) nhóm QC, QH, KM và BH tác động đến NB;
- và (ii) nhóm QC, BH và NB tác động đến TT.
Ngưỡng đánh giá chỉ số VIF được sử dụng phổ biến trong nghiên cứu PLS-SEM như sau:
- VIF lớn hơn hoặc bằng 5 cho thấy khả năng tồn tại cộng tuyến nghiêm trọng và có thể ảnh hưởng đáng kể đến kết quả ước lượng;
- VIF từ 3 đến dưới 5 phản ánh nguy cơ cộng tuyến ở mức trung bình;
- và VIF nhỏ hơn 3 cho thấy mô hình không gặp vấn đề cộng tuyến đáng kể.
Trên phần mềm SMARTPLS 4, chỉ số này được truy xuất từ kết quả PLS-SEM algorithm tại mục Collinearity statistics (VIF), lựa chọn Inner model – List.
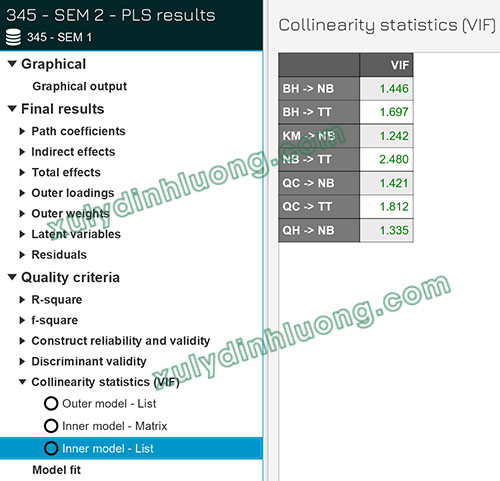
Bảng kết quả VIF được trình bày dưới dạng ma trận, trong đó các cột thể hiện các biến phụ thuộc và các hàng tương ứng với các biến độc lập. Giá trị trong từng ô biểu thị chỉ số VIF của một biến độc lập cụ thể đối với biến phụ thuộc tương ứng.
Trong mô hình ví dụ, chỉ hai cột NB và TT xuất hiện giá trị VIF do đây là hai biến phụ thuộc của mô hình.
- Tại cột NB, các giá trị VIF tương ứng với các hàng BH, KM, QC và QH, phản ánh mức độ cộng tuyến của các biến độc lập tác động lên NB.
- Tại cột TT, các giá trị VIF nằm ở các hàng BH, NB và QC, tương ứng với các biến độc lập ảnh hưởng đến TT.
Kết quả phân tích cho thấy không tồn tại hiện tượng cộng tuyến trong mô hình, do toàn bộ các giá trị VIF của cả hai nhóm biến độc lập đều nhỏ hơn 3. Trong trường hợp xuất hiện biến độc lập có VIF lớn hơn 5, biến đó cần được cân nhắc loại bỏ khỏi sơ đồ mô hình và tiến hành phân tích lại nhằm đảm bảo mô hình không vi phạm giả định về đa cộng tuyến.
2. Đánh giá ý nghĩa các tác động trong mô hình
Sau khi mô hình được xác nhận không tồn tại hiện tượng đa cộng tuyến, bước tiếp theo là xem xét ý nghĩa của các mối quan hệ tác động trong mô hình cấu trúc SEM. Trong phần mềm SMARTPLS 4, việc đánh giá này chủ yếu dựa trên kết quả phân tích Bootstrapping. Các dạng tác động có thể xuất hiện trong mô hình bao gồm tác động trực tiếp, tác động trung gian và tác động điều tiết. Trong đó, tác động trực tiếp luôn hiện diện trong mọi mô hình nghiên cứu, trong khi tác động trung gian và tác động điều tiết có thể xuất hiện hoặc không tùy thuộc vào cấu trúc mô hình cụ thể.
Bảng kết quả Bootstrapping trong SMARTPLS 4 đối với các quan hệ tác động thường bao gồm các chỉ số cơ bản sau:
- Original sample: Hệ số tác động chuẩn hóa ước lượng từ mẫu dữ liệu ban đầu, tương ứng với hệ số đường dẫn trong mô hình.
- Sample mean: Giá trị trung bình của hệ số tác động chuẩn hóa được ước lượng từ tất cả các mẫu lặp lại trong quá trình Bootstrapping.
- Standard deviation: Độ lệch chuẩn của hệ số tác động chuẩn hóa giữa các mẫu Bootstrap.
- T statistics: Giá trị thống kê t dùng để kiểm định ý nghĩa của mối quan hệ tác động theo kiểm định Student.
- P values: Giá trị xác suất của kiểm định t, được so sánh với các mức ý nghĩa thông dụng như 0.05, 0.1 hoặc 0.01, trong đó mức 0.05 thường được sử dụng mặc định.
Trong quá trình diễn giải kết quả, hai chỉ số được quan tâm chủ yếu là P values và Original sample.
Đối với P values: Kiểm định ý nghĩa thống kê của mối quan hệ tác động
Ý nghĩa thống kê của các mối quan hệ trong mô hình có thể được đánh giá thông qua giá trị t hoặc giá trị p. Tuy nhiên, trong thực tiễn nghiên cứu, p-value thường được ưu tiên sử dụng do dễ diễn giải và thuận tiện trong việc so sánh với các ngưỡng ý nghĩa. Phần mềm SMARTPLS cũng mặc định trình bày và hỗ trợ diễn giải kết quả dựa trên p-value.
Mức ý nghĩa được sử dụng phổ biến nhất là 5% (p = 0.05), đồng thời cũng là mức mặc định trong SMARTPLS 4.
- Khi p-value < 0.05, mối quan hệ được xem là có ý nghĩa thống kê.
- Khi p-value ≥ 0.05, mối quan hệ được kết luận là không có ý nghĩa thống kê.
Cần lưu ý rằng, trong trường hợp một mối quan hệ không đạt ý nghĩa thống kê, nhà nghiên cứu không loại bỏ mũi tên hay nhân tố ra khỏi mô hình. Thay vào đó, cấu trúc mô hình vẫn được giữ nguyên và kết luận rằng tác động đó không có ý nghĩa thống kê trong phạm vi nghiên cứu.
Đối với Original sample: Đánh giá mức độ và chiều hướng tác động
SMARTPLS cung cấp hệ số tác động chuẩn hóa của mẫu gốc trong cột Original sample. Hệ số này có giá trị nằm trong khoảng từ –1 đến +1, mặc dù trên thực tế các hệ số thường có giá trị nhỏ hơn nhiều so với các ngưỡng biên này.
- Hệ số mang giá trị dương cho thấy mối quan hệ tác động cùng chiều giữa các biến.
- Hệ số mang giá trị âm phản ánh mối quan hệ tác động ngược chiều.
- Hệ số có giá trị tiến gần +1 thể hiện mức độ tác động dương mạnh.
- Hệ số có giá trị tiến gần –1 thể hiện mức độ tác động âm mạnh.
- Hệ số có giá trị gần 0 cho thấy tác động yếu hoặc không đáng kể.
Trong trường hợp một biến phụ thuộc chịu ảnh hưởng đồng thời từ nhiều biến độc lập, việc so sánh mức độ tác động giữa các biến được thực hiện dựa trên độ lớn của các hệ số tác động. Khi tồn tại cả tác động dương và tác động âm, cần sử dụng giá trị tuyệt đối của hệ số để đánh giá mức độ ảnh hưởng thực tế của từng biến.
a. Tác động trực tiếp (direct effects)
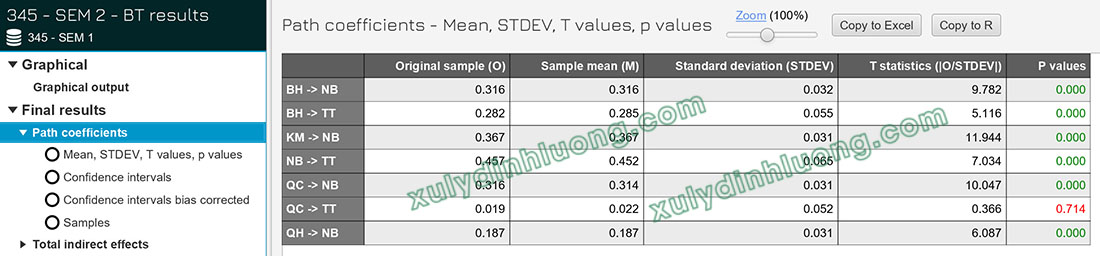
Căn cứ vào kết quả phân tích Bootstrapping trong phần mềm SMARTPLS 4, lựa chọn mục Path coefficients để xem xét kết quả kiểm định các hệ số đường dẫn trong mô hình cấu trúc.
Trong quá trình diễn giải kết quả, trước hết cần xem xét giá trị P-value nhằm xác định mức ý nghĩa thống kê của các mối quan hệ. Kết quả phân tích cho thấy hầu hết các quan hệ trong mô hình đều có ý nghĩa thống kê với P-value < 0.05. Riêng mối quan hệ từ QC đến TT có P-value = 0.714 > 0.05, do đó không đạt ý nghĩa thống kê.
Sau khi xác định ý nghĩa thống kê, hệ số Original sample được sử dụng để đánh giá mức độ và chiều hướng tác động. Kết quả cho thấy tất cả các hệ số đều mang giá trị dương, phản ánh các mối quan hệ trực tiếp trong mô hình đều là tác động cùng chiều.
- Đối với biến NB, mức độ ảnh hưởng của các biến độc lập được sắp xếp theo thứ tự giảm dần như sau: KM (0.367), QC (0.316), BH (0.316) và QH (0.187).
- Đối với biến TT, mức độ ảnh hưởng từ mạnh đến yếu lần lượt là NB (0.457) và BH (0.282).
b. Tác động gián tiếp (indirect effects)
Tác động gián tiếp được đánh giá thông qua kết quả phân tích Bootstrapping tại mục Specific indirect effects nhằm kiểm định các hệ số đường dẫn gián tiếp trong mô hình.
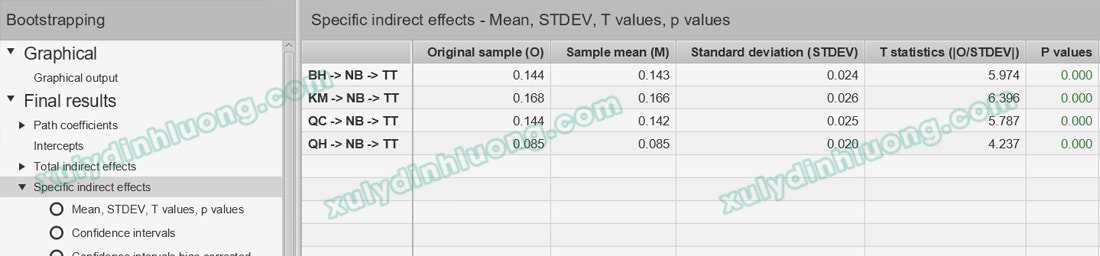
Kết quả Bootstrapping cho thấy tất cả các tác động gián tiếp của BH, KM, QC và QH lên TT thông qua biến trung gian NB đều có ý nghĩa thống kê, với P-value đều bằng 0.000 và nhỏ hơn 0.05 ở tất cả các mối quan hệ.
Xét về độ lớn, các tác động gián tiếp được sắp xếp theo thứ tự từ mạnh đến yếu như sau:
KM → NB → TT đạt giá trị 0.168, là tác động gián tiếp mạnh nhất;
BH → NB → TT và QC → NB → TT cùng đạt giá trị 0.144;
QH → NB → TT có giá trị 0.085, là tác động gián tiếp yếu nhất.
c. Tác động điều tiết (moderating effects)
Tác động điều tiết là một dạng tác động có tính chất đặc thù trong mô hình nghiên cứu. Nội dung phân tích biến điều tiết sẽ được trình bày riêng trong bài viết Phân tích biến điều tiết moderator trong SMARTPLS 4.
3. Hệ số xác định R bình phương (R square)
Hệ số xác định R bình phương (R²) phản ánh mức độ mà các biến độc lập trong mô hình có khả năng giải thích sự biến thiên của biến phụ thuộc. Đối với mỗi biến được xác định là biến phụ thuộc, mô hình sẽ cung cấp một giá trị R² tương ứng nhằm đánh giá sức mạnh giải thích của tập hợp các biến độc lập tác động lên biến đó.
Theo Hair và cộng sự (2017), việc xác định một ngưỡng cụ thể để kết luận R² là “đạt” hay “không đạt” gặp nhiều khó khăn, do giá trị này chịu ảnh hưởng bởi đặc điểm của mô hình nghiên cứu, bao gồm mức độ phức tạp của mô hình (số lượng biến độc lập, sự tồn tại của các mối quan hệ trung gian) cũng như bối cảnh và lĩnh vực nghiên cứu cụ thể.
Về mặt diễn giải
- Giá trị R² càng tiến gần về 1 cho thấy mô hình có khả năng giải thích tốt sự biến thiên của biến phụ thuộc,
- Trong khi giá trị R² gần bằng 0 phản ánh mức độ giải thích của mô hình là thấp.
- Tuy nhiên, không tồn tại một ngưỡng chuẩn thống nhất nào được xem là tiêu chí tuyệt đối để đánh giá chất lượng của R² trong mọi nghiên cứu.
Trong phần mềm SmartPLS 4, bên cạnh hệ số R², kết quả phân tích còn cung cấp hệ số R bình phương hiệu chỉnh (R² adjusted), là chỉ số đã được điều chỉnh nhằm xem xét ảnh hưởng của số lượng biến độc lập trong mô hình. Chỉ số này được cho là phản ánh chính xác hơn năng lực giải thích thực tế của mô hình, do đó thường được ưu tiên sử dụng khi diễn giải kết quả nghiên cứu.
Trong quá trình phân tích bằng thuật toán PLS-SEM, người nghiên cứu có thể truy cập mục R-square để quan sát các giá trị hệ số xác định của mô hình cấu trúc trên SmartPLS 4.
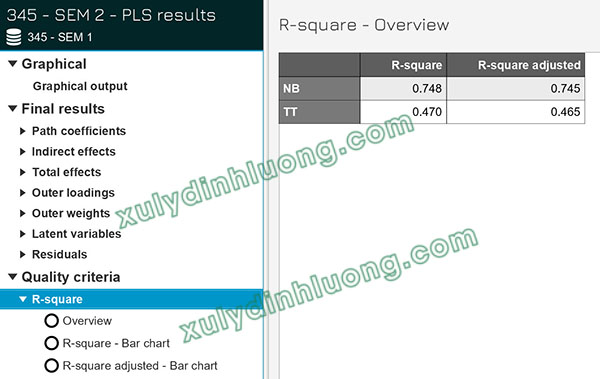
Trong mô hình minh họa, có hai biến giữ vai trò là biến phụ thuộc là NB và TT, tương ứng với hai giá trị R bình phương hiệu chỉnh được báo cáo.
- Cụ thể, giá trị R bình phương hiệu chỉnh của biến NB đạt 0.745, cho thấy các biến độc lập QC, QH, KM và BH giải thích được 73.4% sự biến thiên của biến NB.
- Trong khi đó, R bình phương hiệu chỉnh của biến TT đạt 0.465, hàm ý rằng các biến độc lập QC, BH và NB giải thích được 46.5% sự biến thiên của biến TT.
4. Hệ số f bình phương đánh giá mức độ hiệu quả tác động (Effect size)
Chin (1998) đề xuất công thức tính hệ số f bình phương (f square) nhằm đánh giá mức độ quan trọng và mức độ đóng góp của từng biến độc lập đối với biến phụ thuộc trong mô hình nghiên cứu. Công thức tính toán cũng như bản chất và ý nghĩa của chỉ số này có thể tham khảo thêm trong các tài liệu chuyên sâu về Hệ số Effect Size f2: Ý nghĩa, công thức, cách chạy trên SMARTPLS..
Theo Cohen (1988), các ngưỡng đánh giá hệ số f bình phương được đề xuất như sau:
- f square < 0.02: mức độ ảnh hưởng rất nhỏ, có thể xem là không đáng kể
- f square ≥ 0.02: mức độ ảnh hưởng nhỏ
- f square ≥ 0.15: mức độ ảnh hưởng trung bình
- f square ≥ 0.35: mức độ ảnh hưởng mạnh
Trong thực hành phân tích, sau khi chạy thuật toán PLS-SEM, người nghiên cứu có thể truy cập vào mục f-square để quan sát kết quả trên mô hình cấu trúc trong SmartPLS 4.
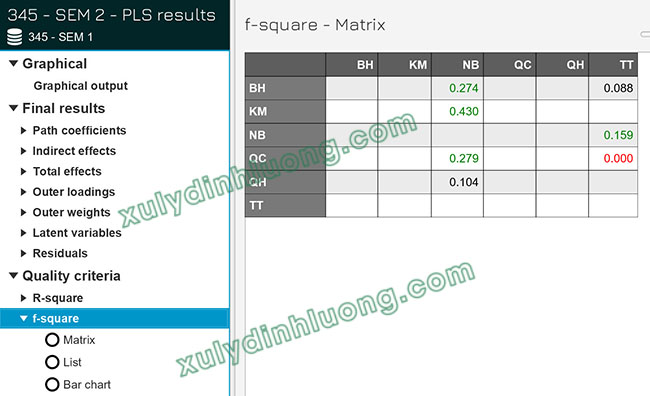
Giá trị f bình phương thường được trình bày dưới dạng bảng ma trận, trong đó hàng đầu tiên thể hiện các biến đóng vai trò là biến phụ thuộc, cột đầu tiên thể hiện các biến đóng vai trò là biến độc lập. Các ô trong bảng là giá trị f bình phương phản ánh mức độ tác động của từng biến độc lập lên từng biến phụ thuộc.
Trong bảng kết quả minh họa, chỉ có hai cột NB và TT có giá trị vì chỉ hai biến này được xác định là biến phụ thuộc trong mô hình. Đối với cột NB, các giá trị f bình phương xuất hiện tại các hàng BH, KM, QC và QH, tương ứng với các biến độc lập tác động lên NB. Tương tự, đối với cột TT, các giá trị f bình phương xuất hiện tại các hàng BH, NB và QC, phản ánh tác động của các biến độc lập này lên TT.
Kết quả từ ví dụ thực nghiệm cho thấy:
- Đối với biến phụ thuộc NB, biến KM có mức độ tác động mạnh, các biến BH và QC có mức độ tác động trung bình, trong khi biến QH có mức độ tác động yếu.
- Đối với biến phụ thuộc TT, biến NB có mức độ tác động trung bình, biến BH có mức độ tác động yếu và biến QC không cho thấy tác động đáng kể.
– Trong nghiên cứu định lượng, khi cần so sánh mức độ tác động tương đối giữa các biến độc lập lên cùng một biến phụ thuộc, hệ số tác động chuẩn hóa thường được sử dụng.
– Ngược lại, khi mục tiêu là đánh giá mức độ ảnh hưởng của từng biến độc lập theo các mức mạnh, trung bình hay yếu, hệ số f bình phương là chỉ số phù hợp và được sử dụng phổ biến.
Bên cạnh các tiêu chí đánh giá nêu trên, nghiên cứu có thể xem xét thêm một số chỉ số khác như hệ số Q bình phương nhằm đánh giá khả năng dự báo của mô hình. Tuy nhiên, do chỉ số này không mang tính quyết định cao trong bối cảnh phân tích hiện tại, nên nội dung này không được đề cập trong phần trình bày này.
Post Views:
16