1. Khái niệm R bình phương
Một chỉ tiêu thường được sử dụng để đánh giá mức độ phù hợp của mô hình hồi quy tuyến tính là hệ số xác định R bình phương (Coefficient of Determination). Việc xác định giá trị R bình phương dựa trên nguyên lý phân tách tổng mức biến thiên quan sát được của biến phụ thuộc thành hai thành phần: biến thiên được giải thích bởi mô hình hồi quy (Regression) và biến thiên không được giải thích, thể hiện qua phần dư (Residual). Khi phần biến thiên do sai số hay phần dư giảm, tức là khoảng cách giữa các giá trị quan sát và giá trị ước lượng từ mô hình nhỏ, thì tỷ trọng biến thiên do mô hình giải thích sẽ tăng, kéo theo giá trị R bình phương lớn hơn.
Hệ số R bình phương có tính chất không giảm khi số lượng biến độc lập trong mô hình tăng lên, nghĩa là việc bổ sung thêm biến giải thích luôn làm R bình phương tăng hoặc giữ nguyên. Tuy nhiên, các nghiên cứu thống kê đã chỉ ra rằng mô hình có nhiều biến độc lập hơn chưa chắc đã mang lại chất lượng dự báo hay khả năng giải thích tốt hơn, do đó việc lựa chọn số lượng biến cần được cân nhắc dựa trên cả ý nghĩa thống kê và cơ sở lý thuyết.
2. R bình phương hiệu chỉnh là gì?
R bình phương hiệu chỉnh có ý nghĩa tương tự R bình phương trong việc phản ánh mức độ phù hợp của mô hình hồi quy. Tuy nhiên, chỉ tiêu này được xây dựng trên cơ sở điều chỉnh từ R bình phương nên thường được ưu tiên sử dụng, đặc biệt trong các mô hình hồi quy tuyến tính đa biến, do khả năng phản ánh chính xác hơn mức độ giải thích của mô hình. Khác với R bình phương, R bình phương hiệu chỉnh không tự động gia tăng khi bổ sung thêm các biến độc lập, mà còn xem xét đến số lượng biến và kích thước mẫu trong mô hình.
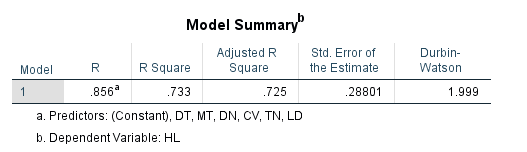
Khi so sánh hai chỉ tiêu như minh họa ở hình trên, có thể nhận thấy giá trị R bình phương hiệu chỉnh (Adjusted R Square) thường nhỏ hơn giá trị R bình phương (R Square). Việc sử dụng R bình phương hiệu chỉnh để đánh giá mức độ phù hợp của mô hình được xem là thận trọng và đáng tin cậy hơn, do chỉ tiêu này hạn chế hiện tượng đánh giá quá cao khả năng giải thích của mô hình.
3. Ý nghĩa của R bình phương hiệu chỉnh
Giá trị của R bình phương hiệu chỉnh dao động trong khoảng từ 0 đến 1. Tuy nhiên, trong thực tiễn nghiên cứu, việc đạt được giá trị bằng 1 là hầu như không thể xảy ra, ngay cả khi mô hình hồi quy được xây dựng với mức độ phù hợp cao.
Xét về mặt ý nghĩa, R bình phương hiệu chỉnh phản ánh mức độ mà các biến độc lập có khả năng giải thích sự biến thiên của biến phụ thuộc trong mô hình hồi quy tuyến tính. Chỉ số này đã được điều chỉnh nhằm khắc phục xu hướng gia tăng giả tạo của R bình phương khi bổ sung thêm biến độc lập vào mô hình.
Trong ví dụ phân tích kết quả hồi quy bằng phần mềm SPSS đã nêu, giá trị R bình phương hiệu chỉnh đạt mức 0.725. Điều này cho thấy các biến độc lập trong mô hình có thể giải thích được 72.5% sự biến thiên của biến phụ thuộc. Phần còn lại 27.5% được quy cho ảnh hưởng của các yếu tố không được đưa vào mô hình và sai số ngẫu nhiên.
4. R bình phương hiệu chỉnh dưới 0,5 (50%)
Hiện nay không tồn tại một ngưỡng chuẩn tuyệt đối cho giá trị R bình phương hiệu chỉnh nhằm khẳng định một mô hình hồi quy là đạt yêu cầu. Về nguyên tắc, giá trị R bình phương hiệu chỉnh càng tiến gần đến 1 thì mức độ giải thích của mô hình càng cao, ngược lại, khi giá trị này tiến về 0 thì ý nghĩa giải thích của mô hình càng hạn chế. Mức R bình phương hiệu chỉnh phụ thuộc đáng kể vào số lượng biến độc lập được đưa vào mô hình để giải thích biến phụ thuộc. Trong trường hợp có nhiều biến độc lập cùng tác động đến biến phụ thuộc Y, giá trị R2 thường được kỳ vọng cao hơn so với mô hình chỉ bao gồm một biến độc lập, do Y được giải thích bởi nhiều yếu tố hơn.
Trong thực hành phân tích hồi quy bằng SPSS, đặc biệt với các mô hình đơn giản gồm nhiều biến độc lập và một biến phụ thuộc, một số nghiên cứu thường sử dụng ngưỡng trung gian 0,5 để phân biệt mức độ ý nghĩa của mô hình, trong đó khoảng từ 0,5 đến 1 được xem là mô hình có mức giải thích tương đối tốt, còn dưới 0,5 được xem là mô hình có mức giải thích chưa cao. Tuy nhiên, cách tiếp cận này chỉ phù hợp trong một số bối cảnh nhất định và việc áp đặt yêu cầu R2 phải lớn hơn 0,5 trong mọi trường hợp là không hoàn toàn phù hợp với lý thuyết thống kê.
Do đó, trong trường hợp kết quả phân tích hồi quy cho thấy giá trị R bình phương hiệu chỉnh nhỏ hơn 50% (0,5), mô hình vẫn có thể được chấp nhận nếu đáp ứng các giả định và mục tiêu nghiên cứu đặt ra.
Trong trường hợp người nghiên cứu gặp khó khăn khi thực hiện phân tích hồi quy do chất lượng dữ liệu khảo sát chưa tốt hoặc mô hình vi phạm các giả định kiểm định, có thể cân nhắc tham khảo các dịch vụ hỗ trợ phân tích SPSS, chẳng hạn như Phạm Lộc Blog hoặc liên hệ qua Zalo 093 395 1549, nhằm tối ưu hóa thời gian thực hiện và cải thiện chất lượng kết quả nghiên cứu.
5. Phương pháp cải thiện giá trị R bình phương và R bình phương hiệu chỉnh trong SPSS
Một trong những kỹ thuật thường được sử dụng nhằm nâng cao giá trị R bình phương và R bình phương hiệu chỉnh trong phân tích hồi quy là nhận diện và loại bỏ các điểm dữ liệu dị biệt, còn gọi là các giá trị ngoại lai, có khả năng làm sai lệch mức độ phù hợp của mô hình.
5.1 Cải thiện R bình phương thông qua đồ thị Scatter Plot trong phân tích hồi quy
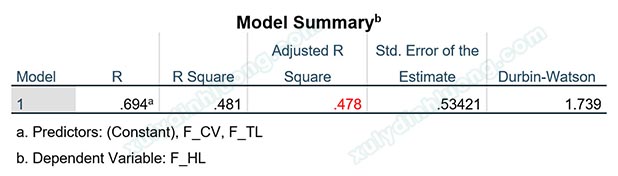
Xem xét một ví dụ phân tích hồi quy tuyến tính bội với hai biến độc lập F_TL và F_CV tác động đến biến phụ thuộc F_HL. Kết quả trong bảng Model Summary cho thấy giá trị R bình phương hiệu chỉnh đạt 0.478. Chỉ số này phản ánh mức độ giải thích của mô hình hồi quy đối với biến phụ thuộc, trong đó giá trị càng tiệm cận 1 thì mô hình càng được đánh giá là phù hợp với dữ liệu nghiên cứu.
Để xây dựng đồ thị Scatter Plot phục vụ cho việc phát hiện các điểm dị biệt, trong quá trình thực hiện hồi quy tuyến tính bội trên SPSS, người nghiên cứu chọn mục Plots, sau đó đưa biến ZRESID vào trục Y và biến ZPRED vào trục X. Việc thiết lập này cho phép quan sát mối quan hệ giữa phần dư chuẩn hóa và giá trị dự đoán chuẩn hóa của mô hình.
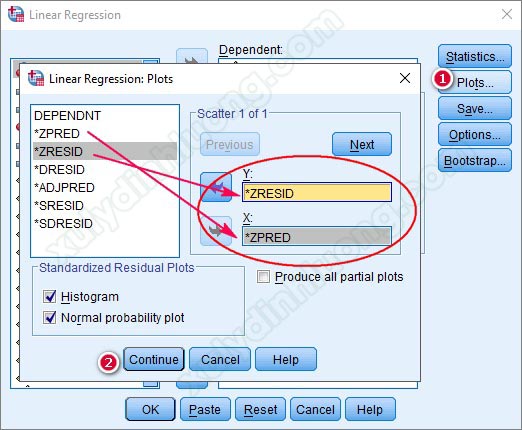
Việc thực hiện phân tích hồi quy cần tuân thủ đầy đủ các bước kỹ thuật nhằm xuất ra toàn bộ các bảng và đồ thị cần thiết cho việc đánh giá kết quả, trong đó đồ thị Scatter Plot đóng vai trò quan trọng trong việc kiểm tra giả định và nhận diện các điểm dữ liệu bất thường.
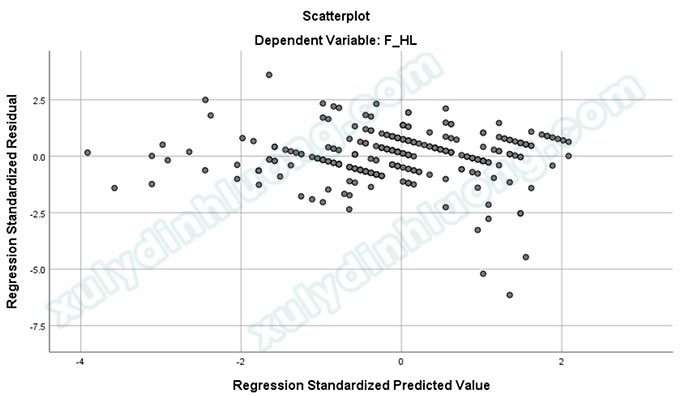
Theo quy luật Empirical, hay còn gọi là quy luật 68-95-99.7 trong phân phối chuẩn, các quan sát nằm ngoài khoảng từ -3 đến 3 trên cả hai trục tọa độ thường được xem là các điểm dị biệt. Những điểm này có thể gây ảnh hưởng tiêu cực đến kết quả hồi quy và làm giảm giá trị R bình phương. Trong đồ thị, có năm điểm nằm ngoài vùng tập trung chính của dữ liệu, được xác định là các điểm dị biệt.
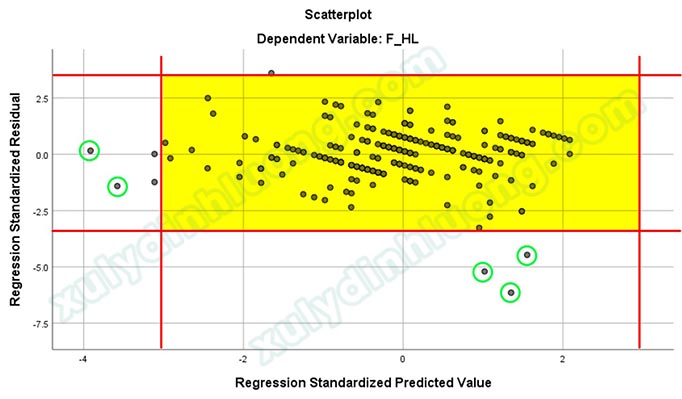
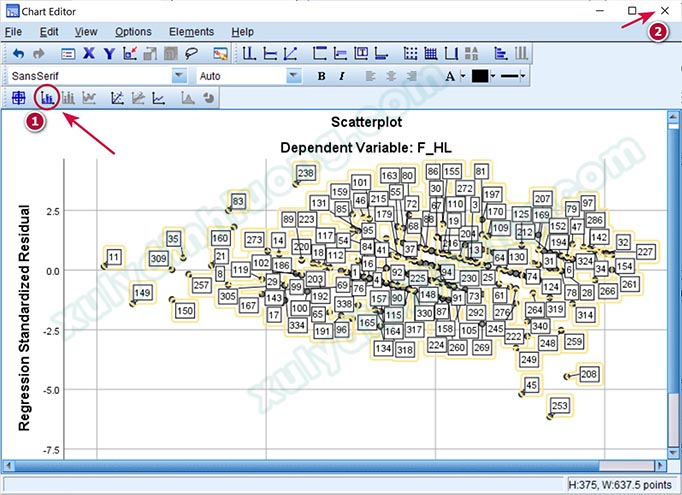
Để xác định cụ thể các quan sát tương ứng với những điểm này, người nghiên cứu có thể yêu cầu SPSS hiển thị tên hoặc mã số của từng quan sát bằng cách chỉnh sửa thuộc tính đồ thị. Chọn vào biểu tượng khoanh tròn như ảnh bên dưới, sau đó nhấp vào nút Close để đóng cửa sổ.
Qua đó, năm điểm dị biệt được xác định tương ứng với các quan sát có số thứ tự 11, 149, 45, 208 và 253.
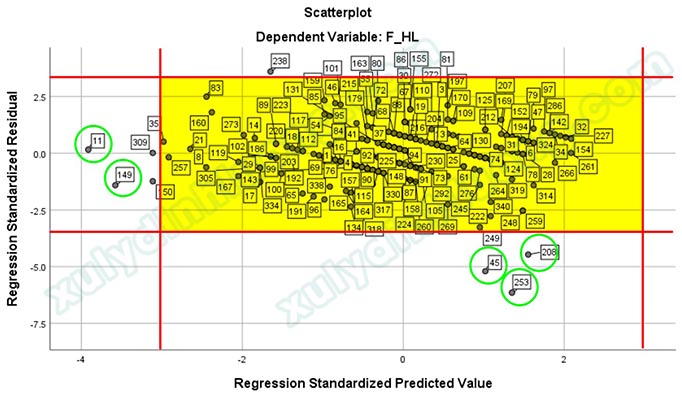
Tiếp theo, năm quan sát này được loại bỏ khỏi bộ dữ liệu. Để đảm bảo độ chính xác trong quá trình xử lý, cần tạo một biến đánh số thứ tự cho các quan sát và thực hiện xóa dữ liệu theo thứ tự từ giá trị lớn đến giá trị nhỏ. Sau khi hoàn tất việc loại bỏ các điểm dị biệt, phân tích hồi quy tuyến tính bội được thực hiện lại trên tập dữ liệu mới.
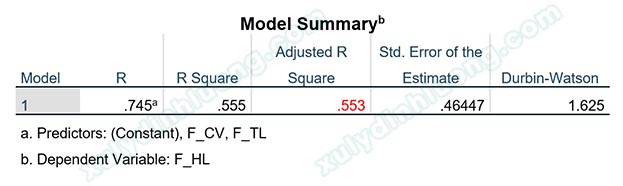
Kết quả cho thấy giá trị R bình phương hiệu chỉnh sau khi loại bỏ các điểm dị biệt tăng lên 0.553, cao hơn đáng kể so với giá trị ban đầu là 0.478. Điều này cho thấy mức độ phù hợp của mô hình hồi quy đã được cải thiện rõ rệt. Mặc dù việc loại bỏ dữ liệu đồng nghĩa với việc giảm số lượng quan sát, nhưng trong trường hợp này, chỉ có 5 quan sát bị loại bỏ trên tổng số 350 quan sát, tỷ lệ này là không đáng kể. Do đó, việc loại bỏ các điểm dị biệt được xem là hợp lý và góp phần nâng cao chất lượng kết quả hồi quy.
5.2 Tăng hệ số R bình phương thông qua bảng Casewise Diagnostics
Trong phân tích hồi quy tuyến tính, phần mềm SPSS cung cấp chức năng tự động phát hiện các quan sát dị biệt nhằm hỗ trợ đánh giá và cải thiện độ phù hợp của mô hình. Cụ thể, trong mục Statistics, người nghiên cứu lựa chọn tùy chọn Casewise diagnostics và thiết lập ngưỡng phát hiện dị biệt bằng cách nhập giá trị 2 hoặc 3 độ lệch chuẩn vào ô Outliers outside. Thông lệ nghiên cứu thường ưu tiên xem xét các quan sát nằm ngoài vùng 3 độ lệch chuẩn trước; trong trường hợp việc xử lý các quan sát này chưa mang lại cải thiện đáng kể cho mô hình, khi đó mới tiếp tục xem xét các quan sát nằm ngoài vùng 2 độ lệch chuẩn.
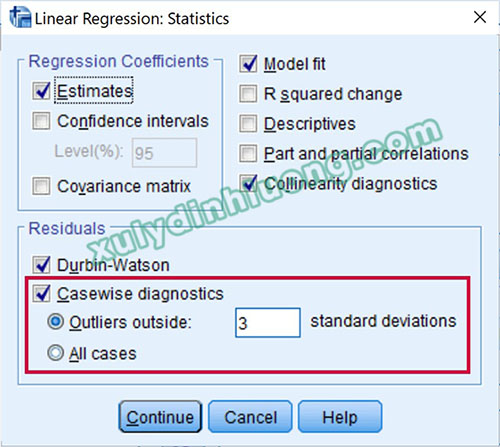
Tiếp tục tiến hành phân tích hồi quy nhằm đánh giá tác động của các biến F_TL và F_CV đến biến phụ thuộc F_HL. Trong bảng Casewise diagnostics, giá trị 3 được sử dụng để phát hiện các quan sát dị biệt vượt quá ngưỡng 3 độ lệch chuẩn. Kết quả phân tích hồi quy cho thấy hệ số Adjusted R Square đạt 0.478, đồng thời bảng Casewise Diagnostics xác định các quan sát dị biệt bao gồm các trường hợp có số thứ tự 45, 208, 238, 249 và 253.
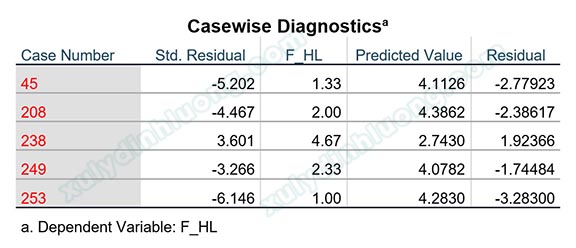
Trên cơ sở kết quả này, năm quan sát tương ứng với các hàng 45, 208, 238, 249 và 253 được loại bỏ khỏi tập dữ liệu. Để đảm bảo thao tác xóa dữ liệu chính xác, cần thiết lập một biến đánh số thứ tự cho các quan sát và tiến hành xóa theo thứ tự từ hàng có số lớn đến hàng có số nhỏ. Sau khi loại bỏ các quan sát dị biệt, phân tích hồi quy tuyến tính bội được thực hiện lại nhằm đánh giá sự thay đổi của mô hình.
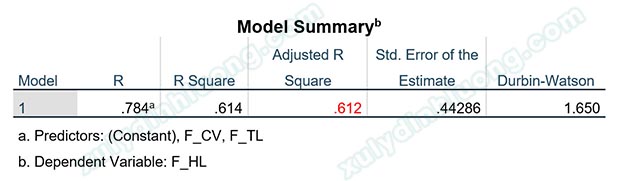
Kết quả hồi quy với tập dữ liệu đã được hiệu chỉnh cho thấy giá trị Adjusted R Square tăng lên 0.612, cao hơn so với mức 0.478 ban đầu. Điều này cho thấy mức độ giải thích và độ phù hợp của mô hình hồi quy đã được cải thiện đáng kể sau khi loại bỏ các quan sát dị biệt.