Hệ số Q² predict (Q Square) trong phần mềm SmartPLS là một chỉ số thống kê được sử dụng để đánh giá mức độ phù hợp dự đoán (predictive relevance) của mô hình PLS-SEM đối với dữ liệu ngoài mẫu (out-of-sample). Chỉ số này phản ánh năng lực của mô hình trong việc tạo ra các dự báo có ý nghĩa đối với những quan sát không được sử dụng trong quá trình ước lượng mô hình ban đầu.
Cụ thể, Q² predict đo lường mức độ mà mô hình PLS-SEM, được xây dựng và ước lượng dựa trên dữ liệu thực nghiệm trong mẫu (in-sample), có khả năng dự đoán chính xác các giá trị quan sát của dữ liệu mới chưa được thu thập hoặc chưa được đưa vào mô hình (out-of-sample). Do đó, Q² predict đóng vai trò quan trọng trong việc đánh giá tính ứng dụng và độ tin cậy của mô hình trong các nghiên cứu thực nghiệm và nghiên cứu dự báo.
1. Năng lực dự báo và hệ số Q²_predict trong SMARTPLS 4
Trong nghiên cứu mô hình cấu trúc, các khái niệm như dữ liệu trong mẫu (in-sample), dữ liệu ngoài mẫu (out-of-sample) và năng lực dự báo (predictive power) thường gây khó khăn trong việc tiếp cận và diễn giải, đặc biệt khi chuyển ngữ sang tiếng Việt do tính trừu tượng của các thuật ngữ này. Do đó, phần này nhằm trình bày khái niệm “năng lực dự báo” liên quan đến chỉ số Q²_predict theo cách trực quan hơn thông qua một ví dụ minh họa thực tiễn.
Giả định một nghiên cứu áp dụng mô hình SERVQUAL, trong đó năm biến độc lập đại diện cho các thành phần chất lượng dịch vụ tác động đến biến phụ thuộc là sự hài lòng đối với chất lượng dịch vụ. Nghiên cứu tiến hành thu thập dữ liệu từ 300 đối tượng khảo sát và đã hoàn tất các bước phân tích, bao gồm đánh giá mô hình đo lường và mô hình cấu trúc theo phương pháp PLS-SEM.
1.1 Dữ liệu trong mẫu (In-sample data)
- Dữ liệu trong mẫu bao gồm toàn bộ 300 quan sát khảo sát được thu thập và sử dụng để ước lượng mô hình bằng phần mềm SMARTPLS.
- Các chỉ số đánh giá mô hình như hệ số xác định (R²) hay các hệ số đường dẫn (path coefficients) đều được tính toán hoàn toàn dựa trên tập dữ liệu này.
Tuy nhiên, việc chỉ xem xét R² của mô hình mới phản ánh mức độ giải thích của mô hình đối với chính 300 quan sát đã sử dụng, mà chưa cho biết khả năng khái quát hóa khi áp dụng cho dữ liệu mới.
Chẳng hạn, trong nghiên cứu nêu trên, mô hình được ước lượng từ 300 mẫu để xác định mối quan hệ từ SERVQUAL đến Sự hài lòng, qua đó thu được giá trị R² của biến Sự hài lòng. Giá trị R² = 0,65 cho thấy mô hình giải thích được 65% mức độ biến thiên của biến “Sự hài lòng” trong phạm vi chính tập dữ liệu 300 quan sát này.
1.2 Dữ liệu ngoài mẫu (Out-of-sample data)
Dữ liệu ngoài mẫu được hiểu là những quan sát không được sử dụng trong quá trình ước lượng mô hình và đóng vai trò như dữ liệu mới để đánh giá khả năng dự báo. Trong thực tiễn nghiên cứu, việc kiểm định này thường đòi hỏi nhà nghiên cứu phải thu thập bổ sung dữ liệu độc lập (ví dụ: thêm 50 hoặc 100 đối tượng khảo sát) nhằm kiểm tra mức độ tổng quát hóa của mô hình. Tuy nhiên, trong phần mềm SMARTPLS, dữ liệu ngoài mẫu không cần thu thập thêm mà được xây dựng thông qua kỹ thuật PLSpredict.
- Cụ thể, trong Q² predict (PLSpredict), SMARTPLS giả lập dữ liệu ngoài mẫu bằng phương pháp chia chéo k lần (ví dụ k = 10 folds) trên bộ dữ liệu gồm 300 quan sát.
- Ở mỗi lần lặp, 270 quan sát được sử dụng làm tập huấn luyện (training set) để ước lượng mô hình, trong khi 30 quan sát còn lại được tạm thời loại ra và xem như dữ liệu ngoài mẫu (test set).
- Mô hình ước lượng từ 270 quan sát sẽ được dùng để dự báo giá trị của 30 quan sát này.
- Sau đó so sánh giá trị dự đoán với giá trị thực tế nhằm tính toán sai số dự báo.
- Quy trình này được lặp lại cho đến khi toàn bộ 300 quan sát đều lần lượt đóng vai trò là dữ liệu ngoài mẫu một lần.
- Cuối cùng, SMARTPLS tổng hợp và so sánh các giá trị dự đoán với các giá trị quan sát thực tế trong các tập “ngoài mẫu tạm thời” để tính toán chỉ số Q² predict.
Do đó, khái niệm “ngoài mẫu” trong trường hợp này không phải là dữ liệu hoàn toàn mới, mà là một phần của dữ liệu gốc được giữ lại và không tham gia vào quá trình ước lượng, chỉ được sử dụng cho mục đích kiểm định khả năng dự báo của mô hình.
1.3. Ý nghĩa của “khả năng dự báo” và hệ số Q²
Hệ số Q² phản ánh mức độ chính xác của mô hình SERVQUAL khi được sử dụng để dự đoán dữ liệu của các đối tượng mới, tức là những khách hàng không thuộc tập mẫu ban đầu gồm 300 quan sát. Chỉ số này cho biết liệu mô hình có khả năng dự báo tốt các giá trị quan sát ngoài mẫu hay không.
Trong bối cảnh Q², khái niệm “khả năng dự báo” không được hiểu theo nghĩa dự báo theo thời gian, mà là khả năng ước lượng chính xác các giá trị của dữ liệu mới chưa được sử dụng trong quá trình ước lượng mô hình. Trong phân tích PLS-SEM truyền thống, hệ số R² chỉ phản ánh mức độ giải thích phương sai của các biến phụ thuộc dựa trên dữ liệu trong mẫu (in-sample). Tuy nhiên, một mô hình có giá trị R² cao vẫn có thể cho kết quả dự báo kém khi áp dụng cho các tập dữ liệu mới ngoài mẫu (out-of-sample).
2. Cốt lõi của chỉ số Q²_predict
Về bản chất, việc đánh giá Q²_predict được thực hiện thông qua so sánh năng lực dự báo của mô hình PLS-SEM với một mô hình mốc (benchmark model), trong đó trọng tâm là so sánh với mô hình Indicator Average (IA).
2.1. Mô hình Benchmark (mốc so sánh)
Trong khuôn khổ PLSpredict, mô hình benchmark được hiểu là một phương pháp dự báo ngây thơ (naïve prediction approach), không khai thác cấu trúc quan hệ nhân quả của PLS-SEM mà chỉ dựa trên các quy tắc thống kê đơn giản. Hai loại mô hình benchmark được sử dụng phổ biến bao gồm:
-
Indicator Average (IA – dự báo bằng giá trị trung bình): Theo cách tiếp cận này, mọi quan sát mới đều được dự báo bằng giá trị trung bình của biến quan sát trong tập dữ liệu huấn luyện. Chẳng hạn, nếu điểm trung bình của biến Sự hài lòng được tính từ 270 quan sát trong mẫu huấn luyện là 3,8, thì giá trị dự báo cho Sự hài lòng của bất kỳ quan sát mới nào cũng được gán bằng 3,8.
-
Linear Model (LM – mô hình hồi quy tuyến tính): Khác với PLS-SEM, mô hình LM không sử dụng cấu trúc mô hình đo lường và mô hình cấu trúc, mà thực hiện hồi quy tuyến tính trực tiếp toàn bộ các biến quan sát độc lập (exogenous indicators) lên từng biến quan sát phụ thuộc (endogenous indicators). Ví dụ, mỗi chỉ báo của biến Sự hài lòng được dự báo thông qua hồi quy tuyến tính từ tất cả các chỉ báo của các biến độc lập.
Mục tiêu của việc sử dụng mô hình benchmark là đóng vai trò đối chứng, qua đó đánh giá liệu mô hình PLS-SEM có thực sự mang lại mức cải thiện có ý nghĩa về năng lực dự báo so với các phương pháp dự báo đơn giản hay không.
2.2. Mô hình PLS (PLS-SEM)
Mô hình Partial Least Squares Structural Equation Modeling (PLS-SEM) được xây dựng và ước lượng bằng phần mềm SmartPLS. Mô hình thể hiện cấu trúc các mối quan hệ đường dẫn giữa các biến tiềm ẩn (latent variables), trong đó mỗi biến tiềm ẩn được đo lường thông qua nhiều biến quan sát (observed indicators).
Mục tiêu của phương pháp PLS-SEM là ước lượng các hệ số đường dẫn (β) giữa các biến tiềm ẩn, đồng thời tối đa hóa khả năng dự báo của mô hình đối với biến phụ thuộc dựa trên các mối quan hệ được giả thuyết hóa về mặt lý thuyết.
Trong nghiên cứu này:
- Mô hình PLS-SEM được thiết lập với cấu trúc: năm thành phần của SERVQUAL tác động đến Sự hài lòng của khách hàng.
- Bên cạnh đó, mô hình được so sánh với hai mô hình chuẩn (benchmark). Cụ thể, mô hình Benchmark IA dự báo mức độ Sự hài lòng của khách hàng mới bằng giá trị trung bình Sự hài lòng quan sát được từ mẫu dữ liệu ban đầu.
- Trong khi đó, mô hình Benchmark LM dự báo từng chỉ báo của biến Sự hài lòng thông qua hồi quy tuyến tính từ toàn bộ các chỉ báo của SERVQUAL, không xét đến cấu trúc mối quan hệ nhân quả giữa SERVQUAL và Sự hài lòng trong mô hình PLS-SEM.
2.3. So sánh PLS với mô hình chuẩn (Benchmark)
Trong phân tích benchmark thường tồn tại hai mô hình đối sánh; tuy nhiên, trọng tâm của so sánh là giữa mô hình PLS-SEM và mô hình trung bình (Indicator Average – IA). Việc đối chiếu chỉ số Q²_predict của PLS-SEM với mô hình trung bình là cần thiết nhằm đánh giá giá trị dự báo thực chất của mô hình. Lý do là bởi nếu mô hình PLS-SEM không cho kết quả dự đoán chính xác hơn so với cách tiếp cận đơn giản nhất – tức chỉ sử dụng giá trị trung bình để dự báo – thì mô hình đó không mang lại ý nghĩa dự báo khoa học.
- Cụ thể, khi Q²_predict > 0, sai số dự báo của mô hình PLS-SEM nhỏ hơn sai số dự báo của mô hình trung bình, qua đó cho thấy mô hình có giá trị dự báo đối với dữ liệu mới.
- Ngược lại, nếu Q²_predict ≤ 0, khả năng dự báo của mô hình không tốt hơn, hoặc thậm chí kém hơn, so với việc chỉ sử dụng giá trị trung bình, hàm ý rằng mô hình không đáng tin cậy cho mục đích dự báo ngoài mẫu (out-of-sample).
Liên hệ với ví dụ minh họa ban đầu về mối quan hệ giữa SERVQUAL và Sự hài lòng với cỡ mẫu N = 300:
- Trong trường hợp kết quả phân tích cho thấy Q²_predict của biến Sự hài lòng đạt giá trị 0,45 (> 0), có thể kết luận rằng mô hình PLS-SEM dự báo tốt hơn đáng kể so với benchmark trung bình, với mức độ dự báo từ trung bình đến cao.
- Ngược lại, nếu Q²_predict của biến Sự hài lòng nhỏ hơn hoặc bằng 0, điều này cho thấy mô hình không mang lại giá trị dự báo vượt trội so với cách dự đoán ngẫu nhiên dựa trên trung bình, đồng nghĩa với việc mô hình chỉ phù hợp với dữ liệu mẫu hiện tại (in-sample) và không có nhiều ý nghĩa khi áp dụng cho dữ liệu mới.
3. Vì sao chỉ số Q²_predict chỉ được tính cho biến phụ thuộc mà không áp dụng cho biến độc lập?
Q²_predict được xây dựng nhằm đánh giá khả năng dự báo ngoài mẫu (out-of-sample predictive power) của mô hình đối với biến phụ thuộc.
Trong khuôn khổ PLS-SEM, biến phụ thuộc (endogenous latent variable) là biến được mô hình ước lượng và dự đoán dựa trên thông tin từ các biến độc lập.
Về bản chất, Q²_predict phản ánh mức độ chính xác của mô hình khi dự đoán giá trị của biến phụ thuộc trên các tập dữ liệu mới thông qua quy trình cross-validation. Do đó, chỉ số này chỉ mang ý nghĩa thống kê đối với các biến phụ thuộc – tức những biến là đối tượng của hoạt động dự báo trong mô hình.
Biến độc lập thì sao?
Ngược lại, biến độc lập (exogenous latent variable) không phải là biến được mô hình dự đoán mà chỉ đóng vai trò là các biến đầu vào dùng để giải thích sự biến thiên của biến phụ thuộc. Các biến này được quan sát trực tiếp từ dữ liệu khảo sát và không chịu sự chi phối của các mối quan hệ cấu trúc trong mô hình. Vì vậy, không tồn tại khái niệm đánh giá khả năng dự báo của mô hình đối với biến độc lập.
Chính vì lý do đó, phần mềm SMARTPLS không tính toán Q²_predict cho các biến độc lập, bởi việc kiểm định năng lực dự báo đối với các biến này là không cần thiết và không phù hợp về mặt phương pháp luận.
Trong ví dụ ở mô hình ban đầu:
- Trong mô hình minh họa ban đầu, SERVQUAL là biến độc lập, được đo lường trực tiếp thông qua các thành phần như Reliability, Responsiveness và Assurance; mô hình không thực hiện dự báo lại giá trị của biến này.
- Trong khi đó, Sự hài lòng về chất lượng dịch vụ là biến phụ thuộc, được mô hình ước lượng dựa trên các thành phần của SERVQUAL.
Do vậy, Q²_predict cho biết mức độ mà mô hình có thể dự báo chính xác sự hài lòng của khách hàng trên dữ liệu mới, dựa trên các biến độc lập đã được quan sát.
4. Phân tích PLSPredict trong SmartPLS 4
Xét một mô hình nghiên cứu minh họa như trình bày bên dưới. Trong mô hình này, hai biến đóng vai trò biến phụ thuộc được sử dụng để đánh giá chỉ số Q² Predict là NB và TT.
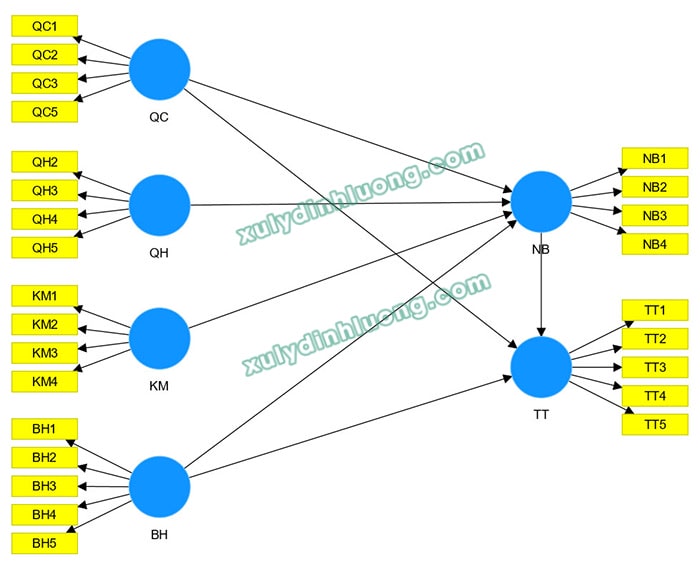
Chỉ số Q² Predict trong SmartPLS 4
Phiên bản SmartPLS 3 chưa hỗ trợ kỹ thuật PLS Predict; do đó, phân tích Q² Predict chỉ có thể được thực hiện trên SmartPLS phiên bản 4. Phần mềm SmartPLS 4 (phiên bản được sử dụng trong ví dụ là 4.1.1.2) cho phép triển khai phân tích này thông qua giao diện tính toán tích hợp.
Để tiến hành, người nghiên cứu truy cập vào menu Calculate và lựa chọn PLSpredict/CVPAT. Sau đó, một cửa sổ thiết lập tham số cho thuật toán cross-validation của PLSpredict/CVPAT sẽ xuất hiện.
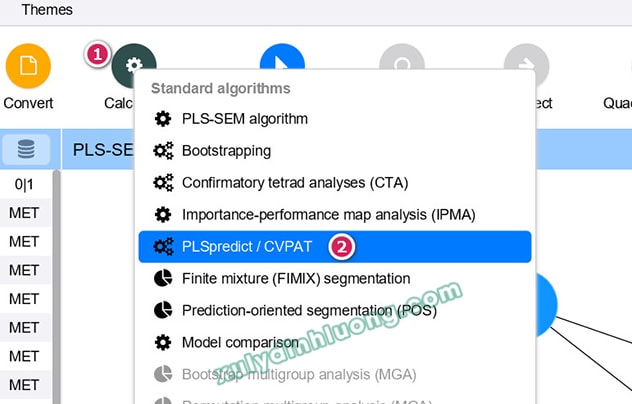
Trước hết, tham số Number of folds (số lượng fold trong k-fold cross-validation) được sử dụng để xác định số phần mà tập dữ liệu sẽ được chia.
- Theo mặc định, SmartPLS 4 thiết lập giá trị này là 10, tương ứng với 10-fold cross-validation. Khi đó, dữ liệu được chia thành 10 phần bằng nhau; trong mỗi vòng lặp, 9 phần được sử dụng để huấn luyện mô hình và 1 phần còn lại dùng để kiểm định, quá trình này được lặp lại cho đến khi tất cả các quan sát đều lần lượt xuất hiện trong tập kiểm định.
- Trong nghiên cứu học thuật, số lượng fold hợp lý thường dao động từ 5 đến 15.
Tiếp theo, tham số No. of repetitions (số lần lặp lại của k-fold cross-validation) xác định số lần toàn bộ quy trình cross-validation được lặp lại với các cách chia fold khác nhau.
- Giá trị mặc định trong SmartPLS 4 là 10. Việc lặp lại này nhằm giảm ảnh hưởng của sự ngẫu nhiên trong quá trình chia dữ liệu, qua đó giúp kết quả dự báo trở nên ổn định và đáng tin cậy hơn.
- Trong thực tiễn nghiên cứu, khoảng 5–10 lần lặp thường được xem là đủ; tuy nhiên, nếu cần tăng độ ổn định của kết quả, số lần lặp có thể nâng lên 20 hoặc 30, đổi lại là thời gian tính toán sẽ tăng đáng kể.
Tham số Random number generator liên quan đến cách tạo số ngẫu nhiên trong quá trình chia mẫu.
- Tùy chọn Fixed seed sử dụng cùng một giá trị seed cho mỗi lần chạy, giúp kết quả có thể tái lập hoàn toàn, phù hợp với yêu cầu minh bạch và tái kiểm chứng trong nghiên cứu khoa học.
- Ngược lại, Random seed cho phép phần mềm tự động chọn seed khác nhau ở mỗi lần chạy, dẫn đến sự dao động nhỏ trong kết quả.
Nhìn chung, các thiết lập mặc định do SmartPLS 4 cung cấp đã được tối ưu cho mục đích nghiên cứu học thuật. Do đó, người nghiên cứu có thể giữ nguyên các tham số này và tiến hành tính toán bằng cách nhấp vào Start calculation.
Sau khi quá trình hoàn tất, cửa sổ kết quả (output) sẽ xuất hiện, trong đó người nghiên cứu cần tập trung vào ba nhóm kết quả chính được đánh số tương ứng như minh họa trong hình.

5. Diễn giải kết quả Q² Predict trong SMARTPLS 4
Theo Hair và cộng sự (2022), tiêu chí đánh giá chỉ số Q²_predict được xác định dựa trên dấu của giá trị này: nếu Q²_predict > 0 thì mô hình được xem là có khả năng dự báo ngoài mẫu. Các nghiên cứu gần đây không còn phân loại Q² thành các mức yếu, trung bình hay mạnh như hướng dẫn năm 2019, do các ngưỡng này chưa phản ánh chính xác năng lực dự báo. Vì vậy, khi báo cáo kết quả Q²_predict trong luận văn hoặc bài báo khoa học, yêu cầu cốt lõi là Q²_predict phải lớn hơn 0.
- Q²_predict ≤ 0 thì mô hình không có khả năng dự báo;
- Q²_predict > 0 thì mô hình có năng lực dự báo.
Phân tích tập trung trước hết vào bảng PLSpredict LV summary, phản ánh kết quả Q²_predict ở cấp độ biến tiềm ẩn đóng vai trò biến phụ thuộc trong mô hình.
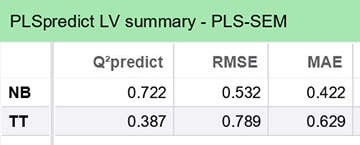
Kết quả cho thấy cả hai biến phụ thuộc NB và TT đều có Q²_predict > 0, qua đó khẳng định mô hình có giá trị dự báo ngoài mẫu.
- Trong đó, NB có Q²_predict = 0,722, thể hiện năng lực dự báo rất cao;
- TT có Q²_predict = 0,387, là giá trị dương và ở mức khá, cho thấy mô hình có khả năng dự báo ở mức trung bình đến khá đối với biến này.
Tiếp theo, bảng PLSpredict MV summary trình bày kết quả ở cấp độ biến quan sát.
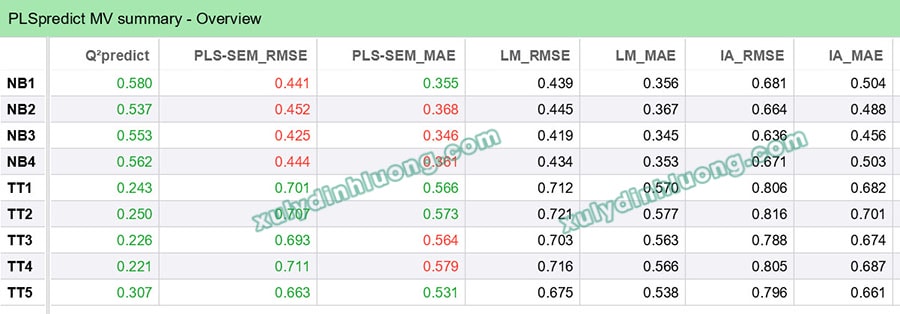
Kết quả cho thấy Q²_predict của toàn bộ các chỉ báo NB1–NB4 và TT1–TT5 đều lớn hơn 0, chứng tỏ tất cả các biến quan sát đều có giá trị dự báo.
Bên cạnh đó, nghiên cứu tiến hành so sánh sai số dự báo (RMSE và MAE) của mô hình PLS-SEM với các mô hình đối chuẩn (benchmark) gồm Linear Model (LM) và Indicator Average (IA). Theo kỳ vọng, nếu mô hình PLS-SEM có RMSE và MAE nhỏ hơn hoặc tương đương các mô hình benchmark, thì năng lực dự báo ngoài mẫu được xem là tốt.
- Kết quả cho thấy đối với các chỉ báo NB1–NB4, RMSE của PLS-SEM (0,425–0,452) thấp hơn so với LM và IA, phản ánh năng lực dự báo mạnh.
- Đối với các chỉ báo TT1–TT5, RMSE của PLS-SEM (0,693–0,711) xấp xỉ hoặc thấp hơn LM và thấp hơn đáng kể so với IA, cho thấy khả năng dự báo chấp nhận được nhưng yếu hơn so với nhóm NB.
Nhìn chung, các chỉ báo của NB có khả năng dự báo mạnh và ổn định, trong khi TT vẫn có giá trị dự báo nhưng mức độ kém hơn, cho thấy mô hình chưa dự đoán tốt TT như NB.
Cuối cùng, bảng CVPAT LV summary – PLS-SEM so với Indicator Average (IA) được sử dụng để kiểm định sự khác biệt về tổn thất dự đoán (prediction loss) giữa mô hình PLS-SEM và mô hình nền đơn giản hơn.
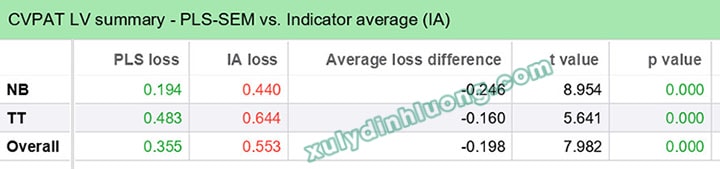
→ Kết quả cho thấy đối với biến NB, tổn thất dự đoán của PLS-SEM (0,194) thấp hơn đáng kể so với IA (0,440), chứng tỏ mô hình PLS-SEM vượt trội so với baseline.
Tương tự, đối với biến TT, PLS loss = 0,483 cũng nhỏ hơn IA loss = 0,644, dù mức chênh lệch thấp hơn so với NB.
Giá trị p = 0,000 cho cả hai biến cho thấy sự khác biệt này có ý nghĩa thống kê, qua đó khẳng định mô hình PLS-SEM có năng lực dự báo thực sự và tốt hơn đáng kể so với mô hình nền.
——
Nguồn tham khảo:
Shmueli, G., Ray, S., Estrada, J. M. V., & Chatla, S. B. (2016). The Elephant in the Room: Predictive Performance of PLS Models. Journal of Business Research, 69(10), 4552-4564.
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2022). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) (3 ed.). Thousand Oaks, CA: Sage
https://smartpls.com/documentation/algorithms-and-techniques/predict
https://github.com/ISS-Analytics/pls-predict